Object Detection
上一个 Vision 时代(前 Transformer?)解决得最好的问题:人脸识别、目标检测、实例分割
我们首先明确:
- Object Detection 的目标是输出一个 bounding box+class
- Instance Segmentation 的目标是输出一个 class+pixel-level mask
Single Object
问题定义 可以下一个定义,bounding box 是使得包括了物体的所有部分且(在平行于 \displaystyle x,y 轴的前提下)面积最小的框;一般情形下允许它不平行会得到面积更优的结果,但在2d下不怎么在乎(也会带来更多麻烦),3d下冗余就太大,我们会允许这时的 bounding box 在 \displaystyle z 轴上可旋转。在这里,bounding box 表示为 Box \displaystyle (x,y,w,h) (四个自由度),综上这样就明确了 task。
分 Branch 的模型和 Loss 计算方法 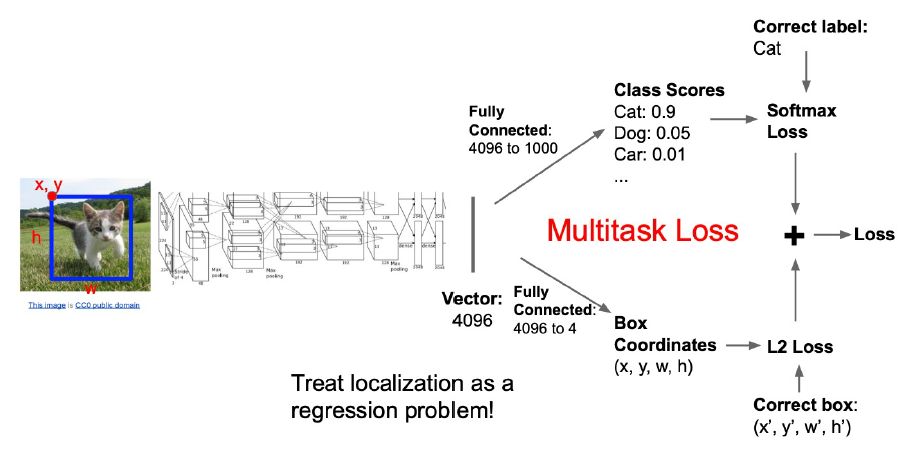
Regression 的两种输出方法:
- 直接把 FC 层的输出当作 Box,这个叫 Linear Activation/No Activation
- 先上 Sigmoid \displaystyle \in (0,1) 再乘上 width, height (直觉是这样更好?)
Regression Loss 的构建方法:
- 先得到 Error \displaystyle \delta x,\delta y,\delta w,\delta h
- L1 Loss \displaystyle \sum |\delta_{i}|
- grad \displaystyle \frac{ \partial L }{ \partial x } 在 (倘若 initial 不巧) 特别大的时候不会直接跑到离谱的地方
- 接近 0 的时候就乱跑了
- L2 loss \displaystyle \sum \delta_{i}^{2} (这个并不是 L2 Norm,当我们谈论范数,它必须和输出同量纲,所以L2 Norm 应该是 RMSE \displaystyle \sqrt{ \frac{1}{N}\sum_{i} \delta_{i}^{2} })
- grad \displaystyle \frac{ \partial L }{ \partial x } 正比于 Error, 能起到一个类似学习率衰减的效果
- initial 到了梯度特别大的地方会跑
- Smooth L1 Loss \displaystyle \text{smooth}_{L_{1}}(x)=\left\{\begin{aligned} & 0.5x^{2}, & \text{if} |x| < 1 \\ & |x|-0.5, & \text{otherwise} \end{aligned}\right.
Multiple Object
输出 bounding box 的数量不确定到底要怎么处理?
远古时代的解决方案 R-CNN, CVPR 2014
用(不含网络的,例如HoG?)传统方法提取可能的box(Region of Interest, RoI),reshape (例如到224x224),再对每个 RoI 做分类(例如用在ImageNet上pretrain的CNN, 或者说当时人们还在用SVM)或者做Single Object Detection
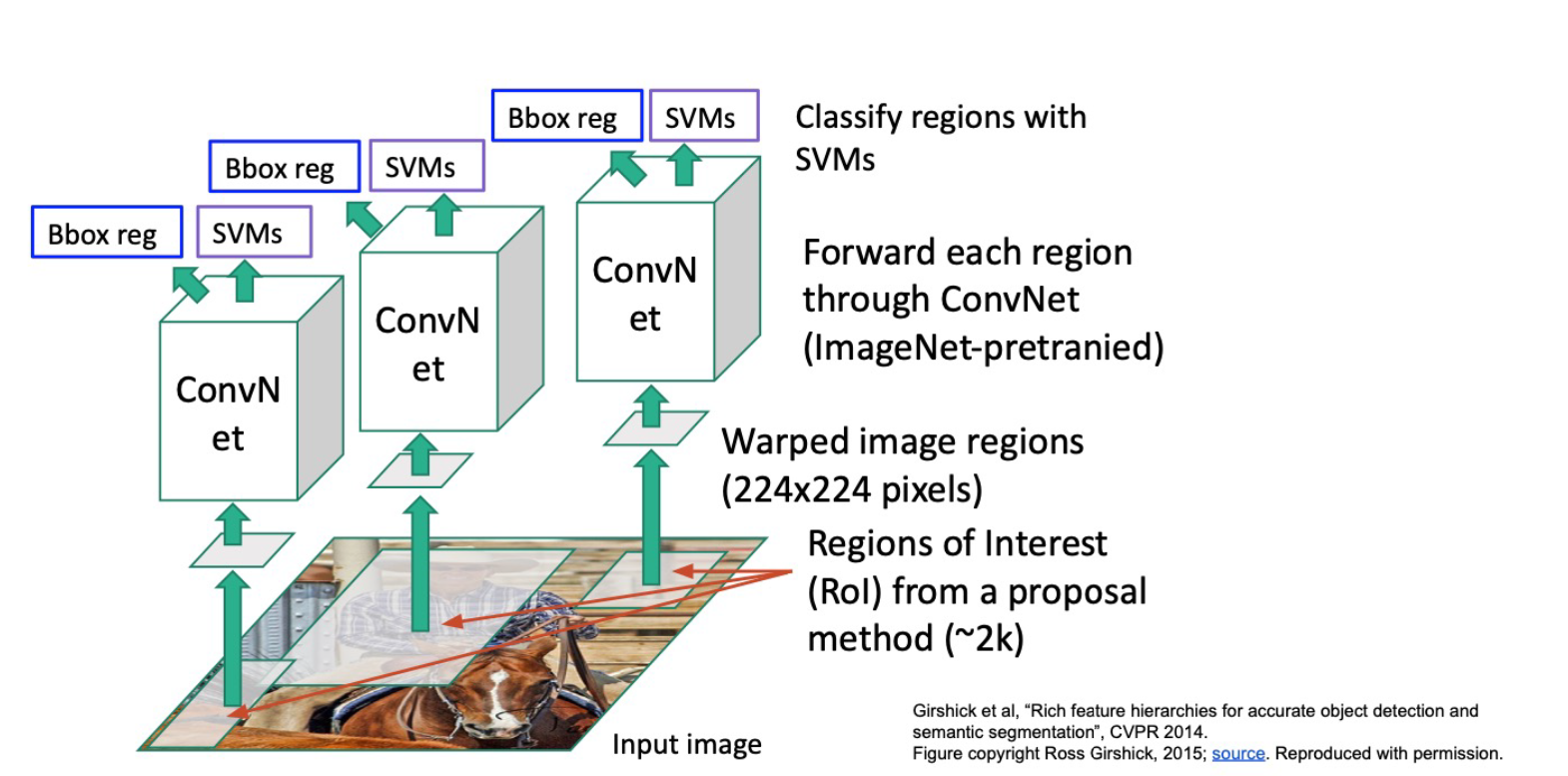
问题:
- 在 Single Object detection 上,如果物体的实际边缘要大于RoI给的Box(这是很可能发生的),我们没有任何办法修正它因为外围信息已经丢掉了
- 很慢,需要做 ~2k 个 RoI 的处理
Fast R-CNN, ICCV 2015
经过ConvNet的feature map会有更广的感受野,所以作者选择在conv5 features上做crop得到RoI->resize->CNN->box&class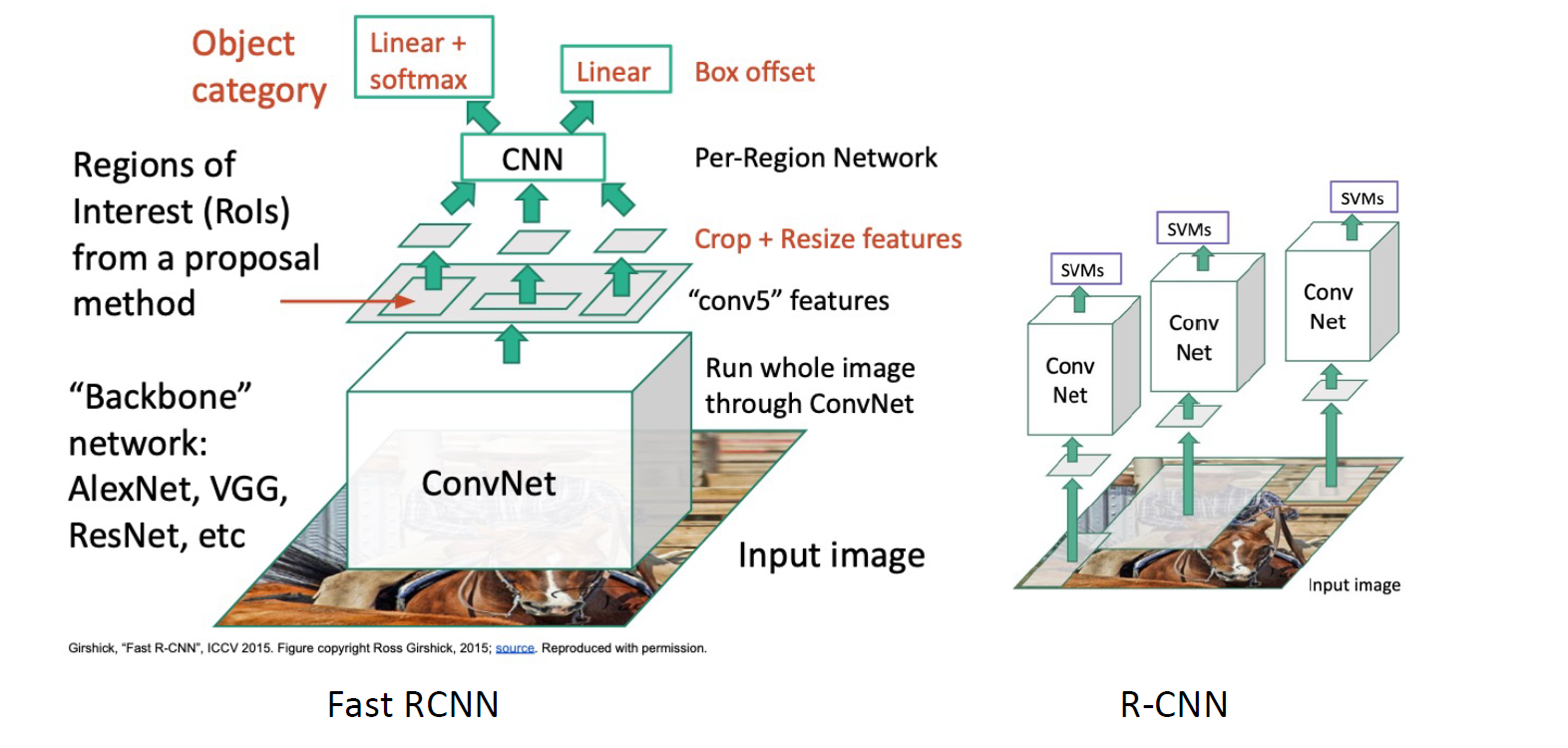
Details 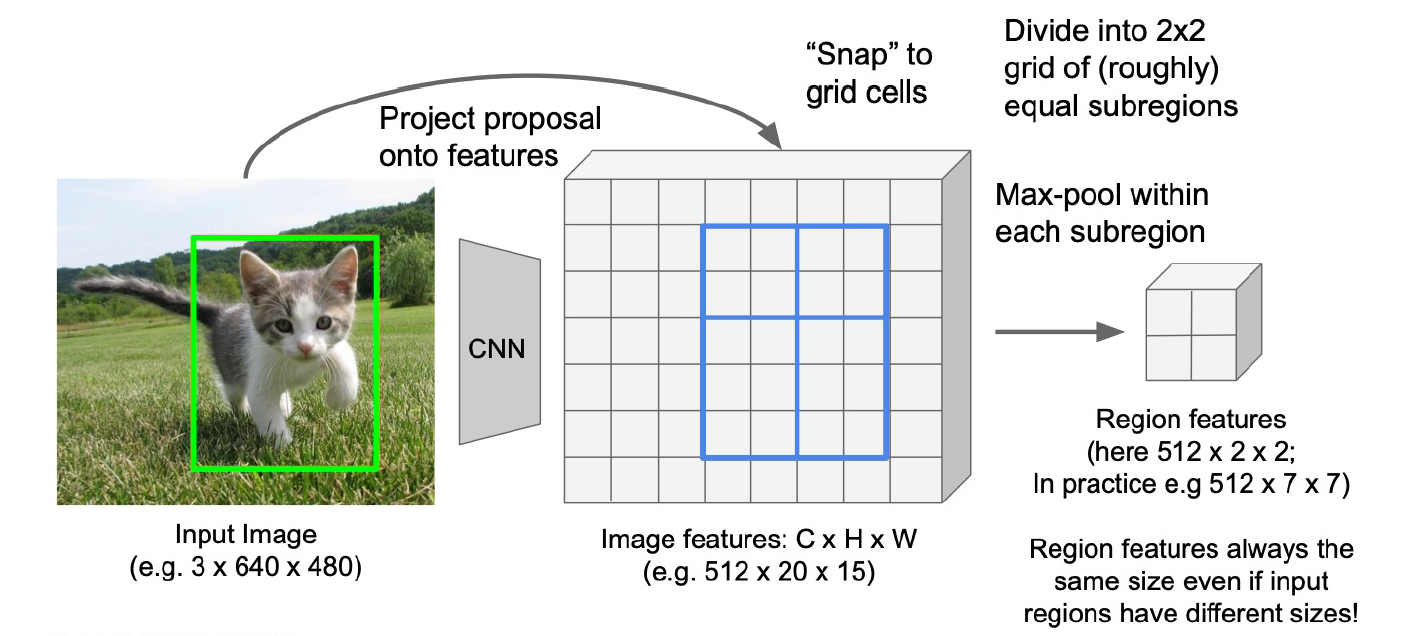
- 用来Cropping的feature map resolution会比原图小,所以要把原图的框「吸附」snap到feature map上,保证axis align
- 要把未知长宽的框reshape成固定shape的region feature,Fast R-CNN的选择是divide 2x2->maxpooling, 结果是\displaystyle C\times 2\times 2
性能分析 
- R-CNN的bottleneck在2k个RoI的CNN,传统方法生成这些RoI只需2s
- Fast R-CNN的bottleneck就在传统方法的部分了!现在对后面的CNN处理只需要~0.32s的时间
- 不过到~2s的数量级,我们开始思考fps的事情了!我们希望能够对一个视频流实时地进行object detection进行追踪;现在的fps: 0.43
Faster R-CNN, NIPS 2015
引入一个CNN来生成Regions of Proposals, Region Proposal Network, RPN,成为一个 Two-Stage 的方法 
RPN如何实现?现在我在feature map上用固定的aspect ratio(感受野大)做anchor box来predict有没有object,生成这里有object为top n/>threshold的box作为RoP。
小总结:现在全是 CNN 了
- image ----CNN----> feature map,这一步提特征,降resolution
- feature map ----RPN----> truth anchor box,这一步跑一遍滑动窗口,预测每一个anchor box的
这里有object的boolean值,给出所有true的predict Box- anchor box+feature map --pooling--CNN----> bounding box+class,这里做单目标的detection,给出 \displaystyle (x,y,w,h) 和 class
实践中,我们设定 \displaystyle K 个可能的anchor box,这样就会生成 \displaystyle K\times H\times W 个可能的框框,取 (例如) possibility top300 作为 true;它的训练需要联合minimize 4个loss
- RPN classify
这里有object - RPN regress box coordinates
- final classify
- final box coordinates
训练起来也特别tricky,需要解决例如正负样本不平衡等很多很多问题,整个task很大程度工程化,需要很强的工程经验->调参,启动!后来人们越来越喜欢端到端的(黑箱的)模型(faster R-CNN 太难训了)。现在的 fps: 2~3
为什么不能端到端?因为取出 top 300 的过程是不可导的。假设越多,先验知识越多,需要数据越少,结构越复杂,工程越恶心;假设越少,泛化能力越强,越端到端,所需数据越爆炸。
YOLO, You Only Look Once, CVPR 2016
YOLO 世界的开端,每个人都能跑的 object detection
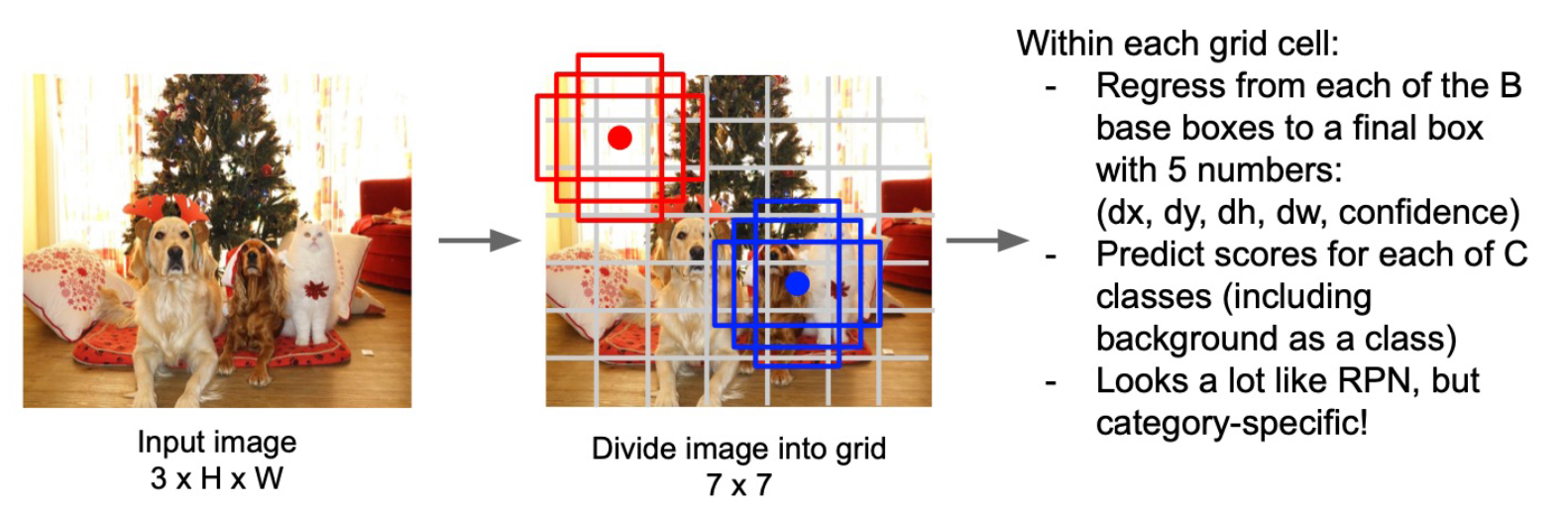
- Image直接分割成很多7x7 cell,在每个cell上搞一堆anchor box
- 把background也当成一类,这样就把
这里有object和class的功能捏一起了,直接在每个anchor-box上CNN,又回到 Single-Stage - 今天的 YOLO fps: 100+
Non-Maximal Suppression, NMS
任务描述 给定一系列 Proposal boxes \displaystyle B 及与之对应的 confidence scores \displaystyle S,给出 IoU threshold \displaystyle \tau,输出一系列经过 NMS 的 bounding box \displaystyle D
最——Naive的方法!
- 确定 confidence scores: (远古时代) 我们把分类得到的 top 1 prob 就当作 confidence score;后来有一些工作改进这个,例如 IoU Net 专门预测我所得到的 bounding box 和 ground truth 之间的 IoU 是多少,把这个当作 confidence score (不过都预测了 IoU 还回来干什么,有点离谱)
- 确定相同 Instance 和不同 Instance: 取 \displaystyle B 里面 confidence score 最高的框框挪到 \displaystyle D,在剩下的 \displaystyle B 里面删除所有和我现在选的这个框框 \displaystyle \text{IoU} > \tau 的,再在剩下的 \displaystyle B 里选出 confidence score 最高的挪到 \displaystyle D ... 重复。
Evaluation
AP
- 设定 IoU 阈值 \displaystyle \tau
- 将检测到的所有框框 \displaystyle D 按照 confidence score 排序
- 比较 \displaystyle D 和 ground truth,IoU > \displaystyle \tau 的认定为 true,反之为 False
- 取第一个框框而假定它是对的,此时 Precision(检出的真值有没有错?) \displaystyle \frac{TP}{TP+FP} = 1 (还没出错),Recall(所有真值有没有漏检?) \displaystyle \frac{TP}{TP+FN}=\frac{1}{N} (漏检还很多)。越往后,检测了的越多,漏检越少 Recall 越大,出错越多 Precision 越小;绘制 Precision-Recall curve,当到模型检测能力极限了,curve就猛猛跌
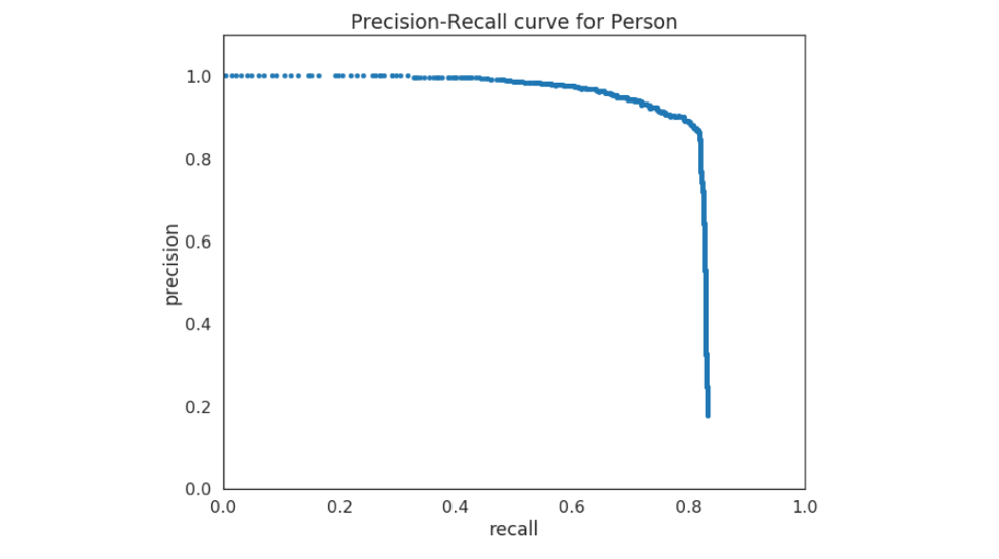
- Recall 越大,结果越好:检得全;Precision 越大,结果越好:出错少。我们想要又全又好,又想要不用超参,从而定义 \displaystyle AP = \int_{0}^{1} P(R) \, dR \approx \sum_{k=1}^{N} P(k) \cdot \Delta R(k),简化地,让 \displaystyle AP=\frac{1}{11}\sum_{i\in\{0,0.1,0.2,\dots,1.0\}}\text{Precision}
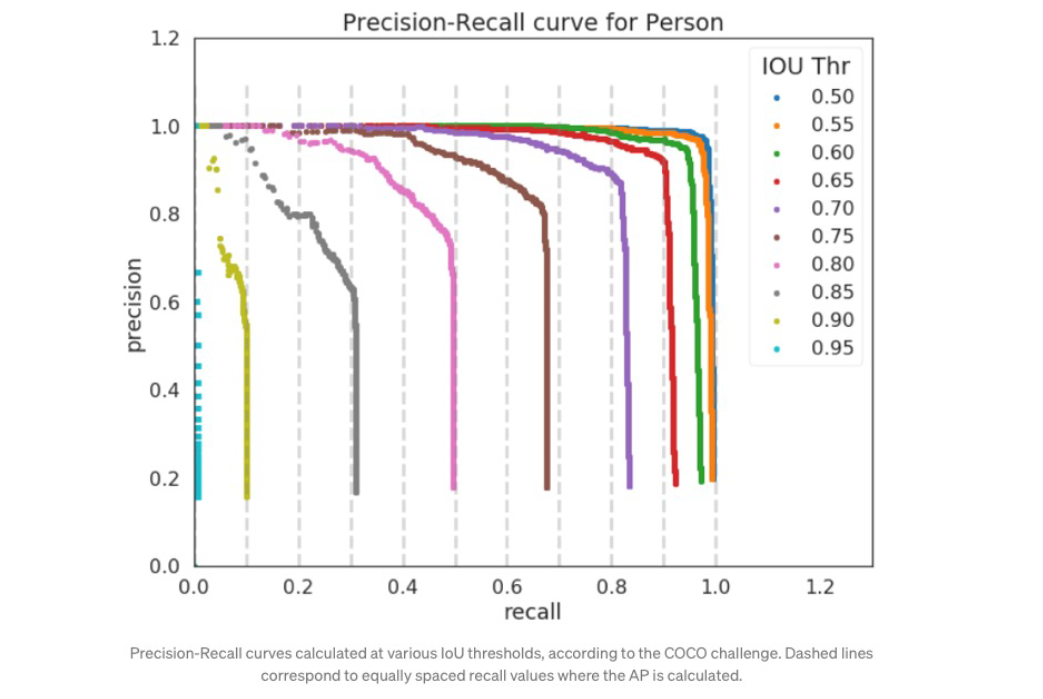
「你知道 IoU=0.95 有多难吗!」老师看起来对此感受颇深
mAP
每个类别,每个 IoU=\displaystyle x\% 可以画一个 Precision-Recall 曲线算一个 \displaystyle AP_x,\displaystyle AP 是所有 \displaystyle AP_{x} 的平均数,\displaystyle mAP 是所有类别 \displaystyle AP 的平均数
Instance Segmentation
两种方式
- Top-down approach: 先detection再在每个框框里mask
- Bottom-up approach: 先mask再对每个mask做classification;本质上是判断每个pixel和周遭的pixel是不是一个instance,对一张image的处理会让一个instance不断扩大;新建instance,instance不断扩大,直到mask完成(自组织,可以想见效果不好)
Mask R-CNN, He et al., ICCV 2017
世人言「baseline!不配发一篇文章!」
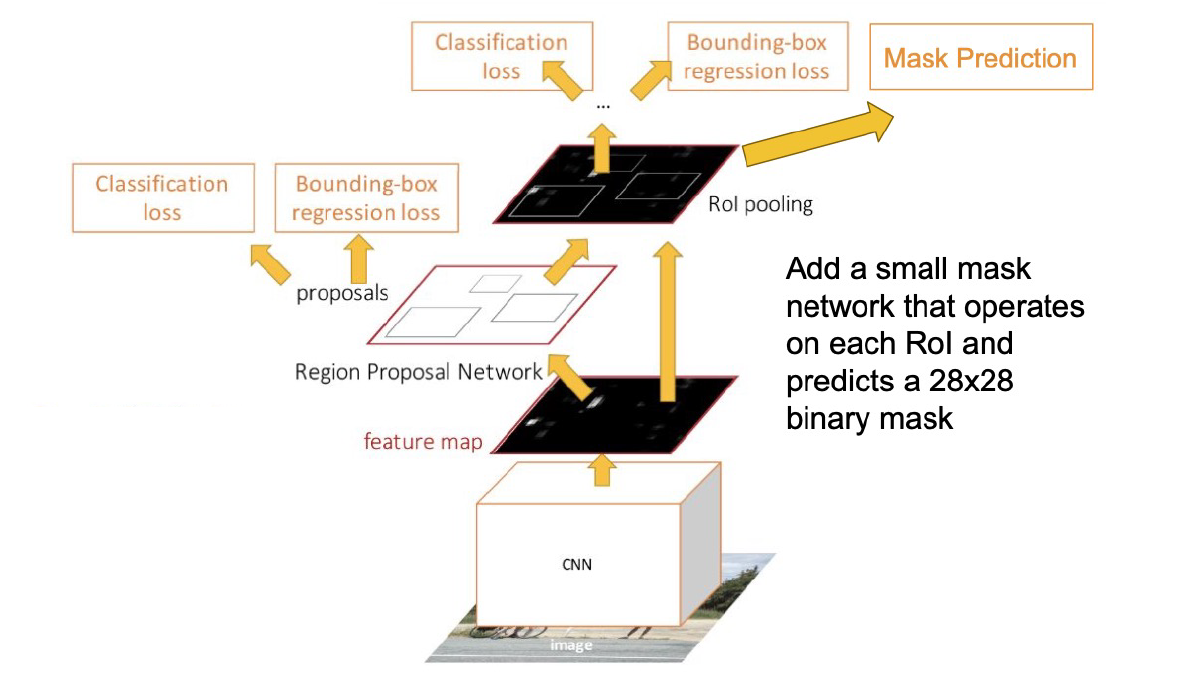
特别的地方:RoI Align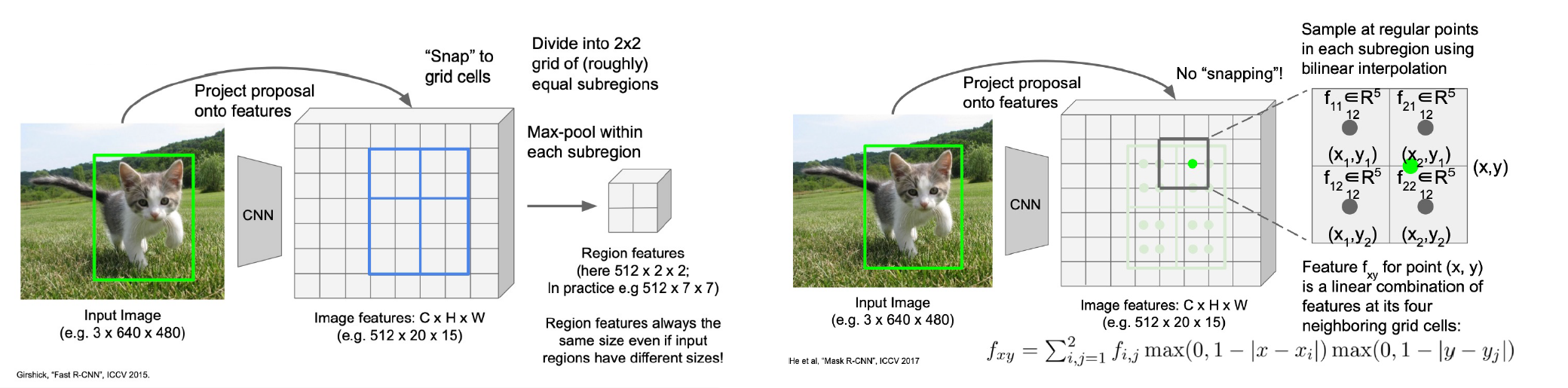
- 一方面,需要segmentation就不能压到2x2那么小,Mask R-CNN选择压到14x14
- 另一方面,吸附是存在information loss的,RoI Pool的结果就会存在一个Shift,边缘不能完全对齐
- 解决:双线性插值
消融实验 Ablation Study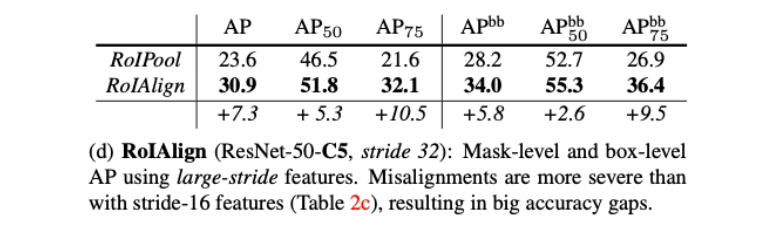
- 在AP50上高一点,AP75上高多一些:RoIAligh决定缝儿有没有对齐,对IoU高的更有效,为故事/motivation的正确性提供了证据
- bounding box 的 AP 也提升了
欣赏结果!
3D
3D的Object Detection会需要\displaystyle ((x,y,z),(w,h,l),(r,p,y))(简化时,让r=p=0, 9->7自由度)
- Frustum PointNet
- VoteNet
无力再讲