Vanilla RNN
Sequential data \displaystyle \{x_{k}\} 方法的两个能力:
- fitting (learning pattern)
- generation
Character-Level RNN Chunk
Too deep
从上次结束的地方继续开始:RNN 网络太深了!trick是用一个chunk (len = \displaystyle t)来限制活跃RNN的深度,我们只在chunk内进行\displaystyle t次forward和\displaystyle t次backpropagation;自然发生问题,\displaystyle h_{0} 从哪里来?
- chunk trick: forward从头跑全但backpropagation只做\displaystyle t步
这样我们就从头到尾做一遍forward,然后随便选一个chunk,它的第一个\displaystyle h设定成\displaystyle h_{0}并让他no_grad不求导。
分析RNN的receptive field/因果性,\displaystyle h_{t} 的receptive field是从0到t的信息,符合时间的流向/因果关系。语言模型有时候用双向RNN,从左到右传播一个\displaystyle h_{t},从右到左传播一个,这样的receptive是真的context上下文,但违背因果不能生成了。
很容易知道每个iter都要对全部context做一遍forward(\displaystyle h会更新)而且几乎不能并行,这是不能接受的。没办法,大家还是让\displaystyle h_{0}initialize成0;but at what cost?金鱼只有七秒记忆,这时候所有\displaystyle h的receptive field只有chunk长了,sequence length不够,这让长文本记忆就很差了/没有任何逻辑性(到现在也没有很大改进)。
Sampling
Too Rigid
- greedy sampling: 每次argmax生成下一个字符,结果是决定性的,绝无变化
- weighted sampling: 生成的概率分布作为weight,随机取样;问题是小概率sample到真的错误的不存在的next token(这里是在说字符)
- Exhaustive Search: 如公式这样生成weighted sampling的概率分布,你知道这样相当于每次生成下一个字符我们都回溯过去将整句话更新为更好的话(让我想到降临的language),问题是TOO EXPENSIVE
- Beam Search: 又像上面的chunk trick,each timestep, we only keep track of \displaystyle k most probable path, 这样每次的前一步可能性只有 \displaystyle k 个,每次的选择空间只有 \displaystyle k^2,取出其中的 top \displaystyle k path,不一定是最好的 optimal,但是更加 efficient
一般在生成任务里,Beam Search 是比较常见的
Embedding
Too Big
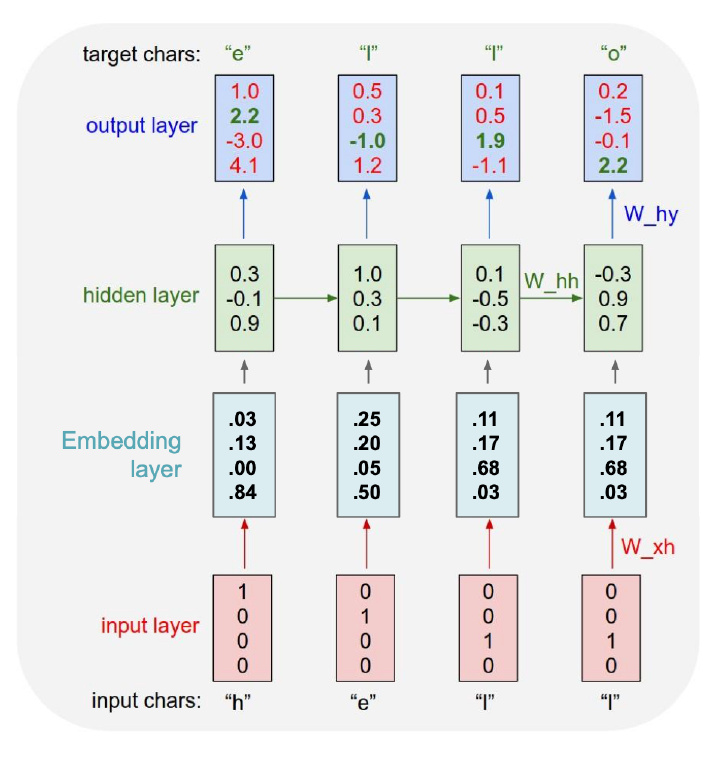
One-Hot 太痛苦,所以我们添加一个 Embedding Layer 转换成维度更小的向量。这个问题叫 Word Embedding/词嵌入,就我们而言可以直接hugging face可用的预训练编码
Multilayer RNNs
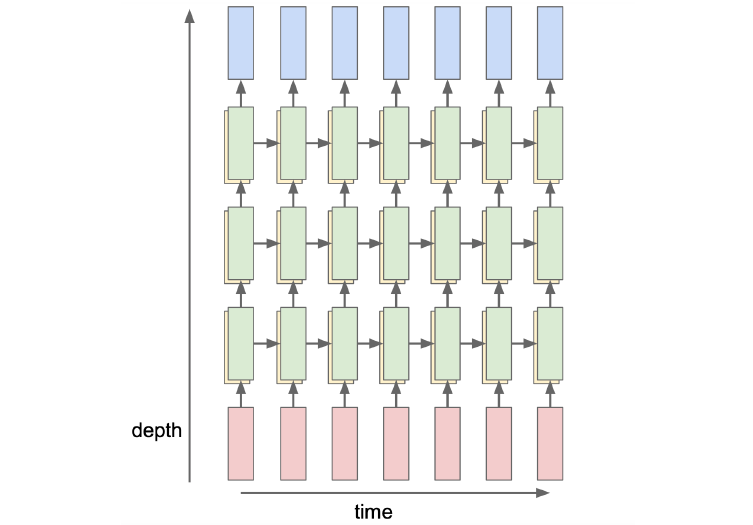
\displaystyle h_{t} 向两个方向的深处传播,会提高模型的capacity(不能解决 RNN 的真正痛点)
BP
Too Forgetful
我们定义共用的权重的偏导 \displaystyle \frac{ \partial L }{ \partial W }=\sum_{t=1}^{T}\frac{ \partial L_{t} }{ \partial W },而 \displaystyle \frac{ \partial L_{T} }{ \partial W }=\frac{ \partial L_{T} }{ \partial h_{T} }\left(\prod_{t=2}^T \frac{ \partial h_{t} }{ \partial h_{t-1} }\right)\frac{ \partial h_{1} }{ \partial W },很容易想到这就会发生梯度消失的问题,具体而言,\displaystyle \frac{ \partial h_{t} }{ \partial h_{t-1} }=\tanh ^{\prime}(\dots)=\cosh^2x\leq 1。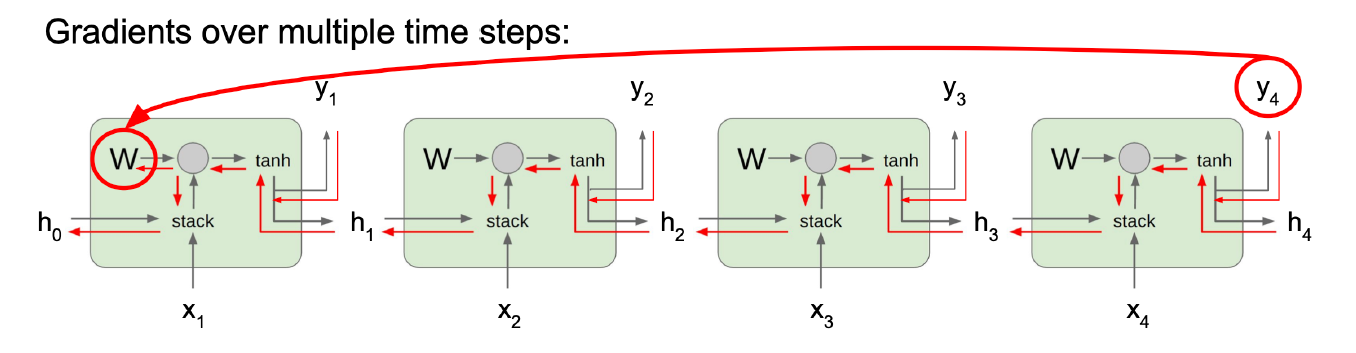 就是不加 tanh 只有 \displaystyle W 也不行 (且不说non-linear没有了),最大奇异值>1即爆炸,<1即归零。大于某个threshold的grad做缩放(Gradient Clipping)也不能解决小的grad,我们不能放大小的grad。
就是不加 tanh 只有 \displaystyle W 也不行 (且不说non-linear没有了),最大奇异值>1即爆炸,<1即归零。大于某个threshold的grad做缩放(Gradient Clipping)也不能解决小的grad,我们不能放大小的grad。
结果就表现为
- 只有金鱼的记忆 (永远不会记得她要print tickets)

- 生成毫无意义的材料

早在2015年甚至更早,人们就能利用RNN生成一些看似合理的code/latex/poem等等,由于权重 \displaystyle W 是复用的,RNN 能够处理任意长的输入,与 model_size 无关,具有「个性」。但是受限于我们刚才所讨论的sequence length & gradient vanishing,RNN没有长距离记忆(可能超过10个词就忘了),从而也不表现出任何「智力」。
LSTM
我们已经知道 ResNet 了,所以很好想到解决问题就是要 skip link。可惜 (Bengio et al, “Learning long-term dependencies with gradient descent is difficult”, IEEE Transactions on Neural Networks, 1994) 就知道了 RNN 有这样的问题。1997 年 Hochreiter 提出了 Long Short Term Memory,启发自人类的记忆方式,部分也有skip的思想,部分地解决了长程记忆问题。
忘却之门
LSTM 采用以下策略:
其中,
- cell state & hidden state \displaystyle c_{t}, h_{t}\in \mathbb{R}^n
- gates \displaystyle i,f,o,j \in \mathbb{R}^n
- \displaystyle i_{j}, f_{j}, o_{j} \in (0,1) (sigmoid gate)
- \displaystyle g_{j} \in (-1,1) (tanh gate)
- Element-wise 乘积 \displaystyle \odot
- gate gate 决定 how much to write to cell
- input gate 决定 whether to write to cell
- forget gate 决定 whether to erase cell
- output gate 决定 how much to reveal cell
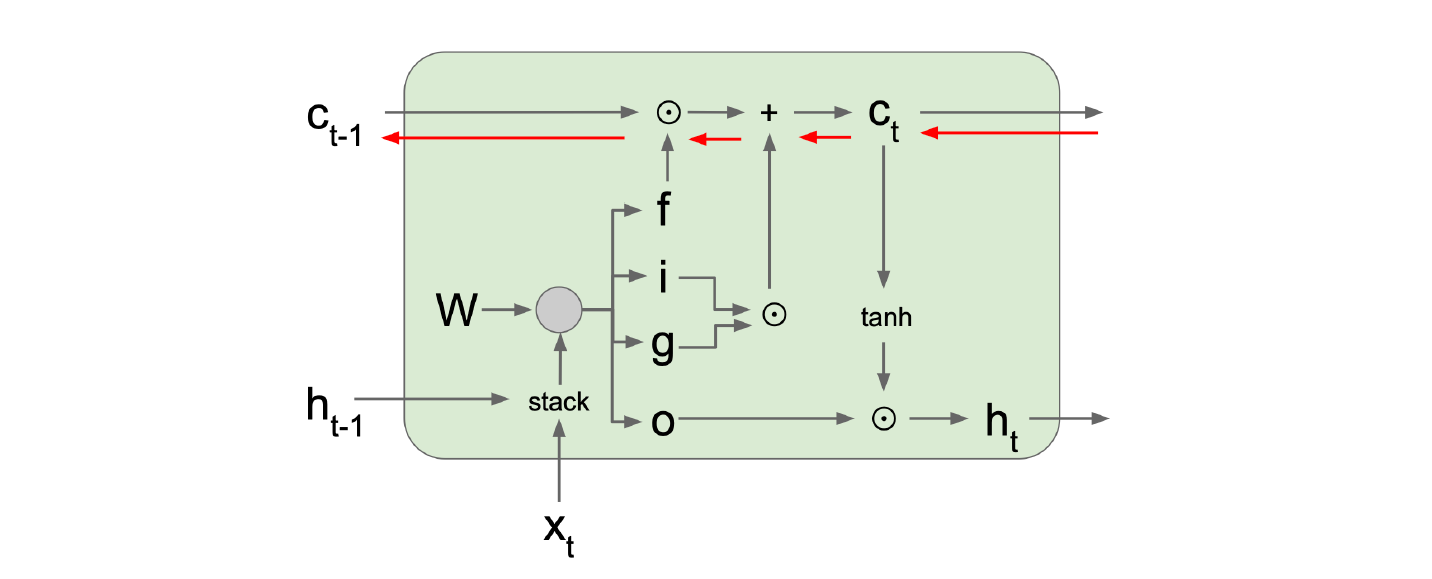
- 带擦除的加性构成长程记忆
- 长程记忆的通路基本上是畅通的
GRU
(Learning phrase representations using rnn encoder-decoder statistical machine traslation, Cho et al., 2014)
简化了4个gates和2个states冗余的部分。
Sequence to Sequence
典型任务:翻译
在many to many里特殊的部分是要全看完再开始输出。(Sutskever et al, “Sequence to sequence learning with neural networks”, NeurIPS 2014) 给出了解决方法,希望先咀嚼RNN所有输入作为\displaystyle c,再喂给输出RNN;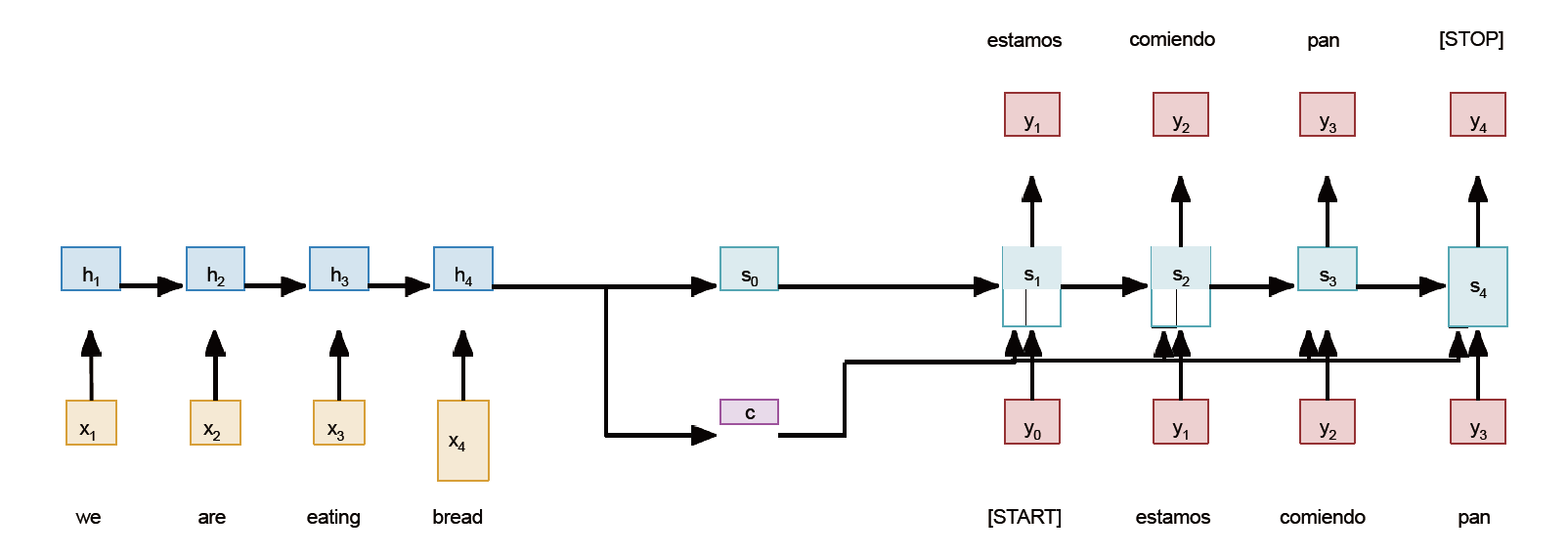
- \displaystyle s_{0} 是 (例如) Initialize 到 0 的
- 需要加上
[START][STOP]标记 - 其实是一个 Encoder \displaystyle h_{t}=W(x_{t}, h_{t-1}) & Decoder \displaystyle s_{t}=U(y_{t-1},s_{t-1}, c)
问题是所有输入信息只被一个单薄的 \displaystyle c 来承担;Decoder 也需要长程记忆机制(代词指代)。
Image Captioning
多模理解的历史
NLP 的数据要远比 CV 多;一个人类一生产生的文字有很多都在互联网上,一个人一生看到的全部内容几乎没有任何在互联网上,NLP 比 CV 更加成熟。(或许因此) CV 的很多内容都可以来自 NLP。举 Image Captioning 为例子,Image 过一个 CNN 就能作为 \displaystyle c 交给 Encoder 生成 Caption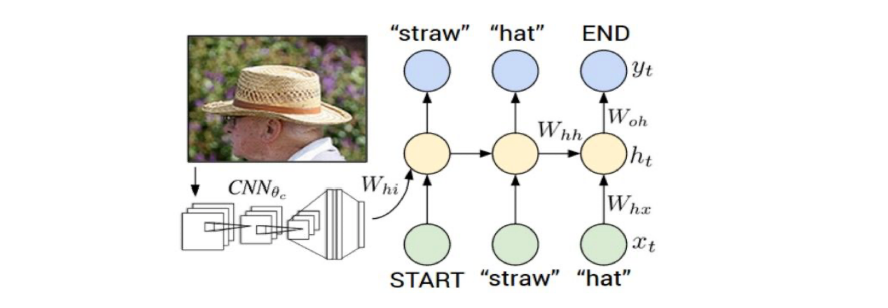
- 要让 Loss 从末尾一路经过 RNN BP 到 CNN 里简直是疯狂,训练的代价会很大
- CNN Pretraining 在例如 ImageNet 上做面向分类的预训练,很容易想到代价是损失了泛化能力,一种办法是把 CNN Pretrain 完 -> 打开一部分再训练。CNN Pretrain 是很重要的一个应用,有很多不用打标签就能进行的 Pretrain 像 Contrastive Learning/Clip etc.
Visual Question Answering (VQA)
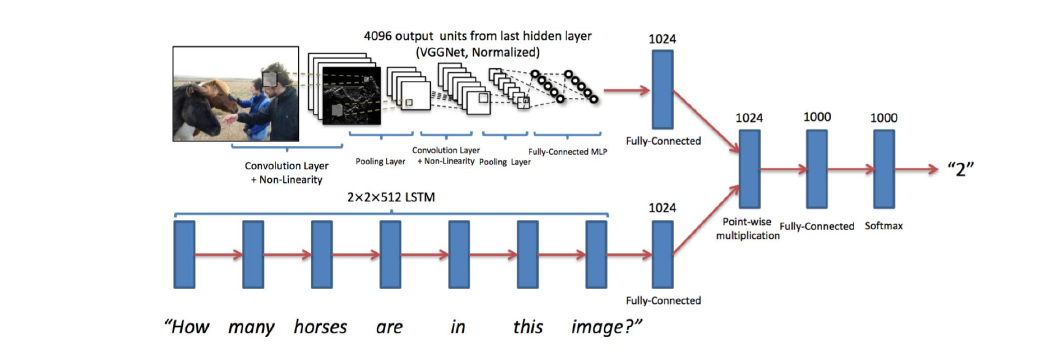
CNN+(双向+双层 2x2(不需要保证因果))LSTM Point-wise Multiplication->Output,这里只输出一个数字,你当然也能用上面的Encoder输出一句话
我们手里整合 (Fusion) 两种信息的方法
- \displaystyle + addition
- \displaystyle \odot concatenation
- \displaystyle \otimes element-wise multiplication
Multi-modal/modality understanding!
这个结构能很好地达到multi-modal的目的吗?不可以,CNN提取信息的过程绝没有受到问题的影响,你不能保证/甚至做不到任何抽出来的feature包含了LSTM需要的信息。这里也是先做 Pretrain 再合并打开一部分训练,跨模态也是个 (还有很多要做的) 的领域。
对 architecture 要有敏锐的批判能力
Attention
Decoder 想要看到所有输入,早期的 Attention 机制出现了
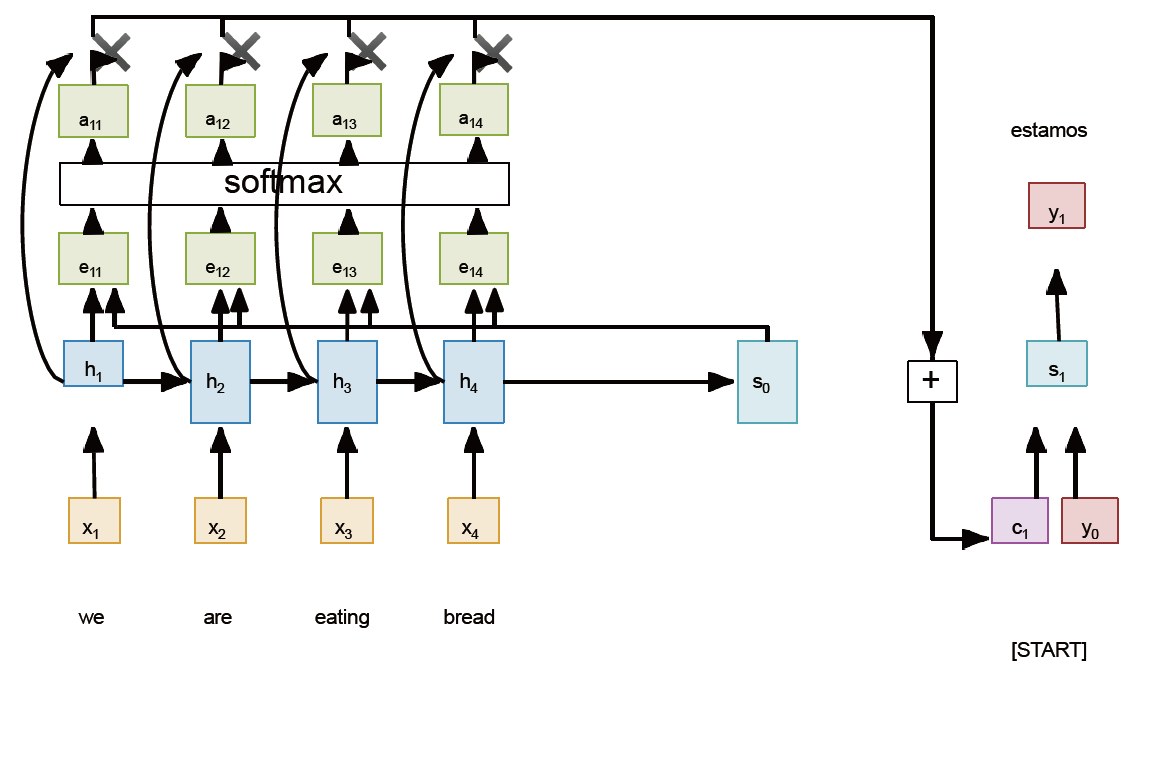
- 通过一个 MLP \displaystyle f_{att} 生成 alignment score \displaystyle e_{t,i} = f_{att}(s_{t-1}, h_{i})
- Normalize/Softmax 它来得到归一化的 attention weights \displaystyle a_{t,i} \in (0,1)
- 把 \displaystyle h_{t} 和 \displaystyle a_{t,i} 求乘积和得到要喂给 \displaystyle s_{t} 的 \displaystyle c_{t} (这决定了我要更在意哪个词!)
- \displaystyle s_{t} = U(y_{t-1}, s_{t-1}, c_{t})