想法
-
data augmentation/boost:
- 降噪
- 混合
-
how would unlabeled soundscape help?
- 特征匹配?这个pipeline应该只会扩大误差?
- 混合不改变原有分类结果(但多了其他的)
- 关键的区别在于这些site录音情况有差异
-
model?
Past best solution
BirdCLEF 2024 5th
A 在时域上应用hgnetb0(3/5 folds),B 频域上应用efficientnetb0(1/5 folds),C 直接torch.cat时域hgb0和频域effb0结果,再加一个fc层(1/5 folds),按5:4:1组合,Score:0.687173
细节:
- 5s x 32kHz = 160000,所以时域是 bsz x 160000 => bsz x 80000 x 2 => bsz x 2 x 80000 => bsz x 2 x 1000 x 80 why??✅
- 使用Mel频谱
torchaudio.transforms.MelSpectrogram✅ - mix的最后上了个fc✅
- 用openvino提速
- preprocess做了归一化✅
作者 COOLZ 独辟蹊径地使用raw signal,作者认为1d信号reshape到2d再上conv2d+padding能够比conv1d更好地捕获时序信号的(长距离?)位置信息,而且既然用conv2d就有很多好的pretrain的模型可以用了,1dcnn比较稀缺
BirdCLEF 2024 4th
共性之处:
- mel频谱+signal
- openvino + int8 quant
引入这些模型:
- A: 2021-2nd Mel CNNs
- 甚至在 2021/2022/2023 的 dataset 上做了预训练
- mel设置基本相同
- Aug:
- BgNoise(作者引入了一个dataset的noise)
- Gain(+/- dB)(这个应该有用)
- Noise Injection
- Gaussian Noise
- Pink Noise
- Mixup
- B: Simple Mel CNN
- C: Raw Signal CNN(灵感来自去年的 coolz)
对这些结果加权平均+几何平均0.15*Model B + 0.25*Model A (rexnet_150) + 0.3*Model A (seresnext26ts) + 0.3*Model C+(0.15*Model B + 0.25*Model A (rexnet_150) + 0.3*Model A (seresnext26ts) + 0.3*Model C) + 0.3*(Model A (rexnet_150) * Model C)**(0.5)
更多trick:
- TTA: 考虑到4min的test soundscape是时间上连续的,鸟总会开始叫——直到停,作者提出了除了预测标准的5秒片段(0-5s,5-10s...),还预测偏移2.5秒的片段(2.5-7.5s,7.5-12.5s...)的方案,再整合,提高连续性(类似upsampling?)
反馈:训练时间翻倍但是涨点有限 - moving avg
- 作者认为同一段音频里一种鸟要叫就会叫多次,否则不存在,所以如果一种鸟在48个bin里叫了的概率都小于0.1,就再手动把这个值减半;如果至少有一次>0.1,就不动它
EfficientNet (2019)
我们在决定CNN的depth, width(channels), resolution(hxw)上遇到了很多困难,很多时候我们拍脑袋的结构不起作用而调用VGG/ResNet看似相似的结构就起到了很好的效果,这让我们思考能不能Auto地获得模型的结构;但这些参量搜索空间过大以至于不可能搜索得到合适的结构。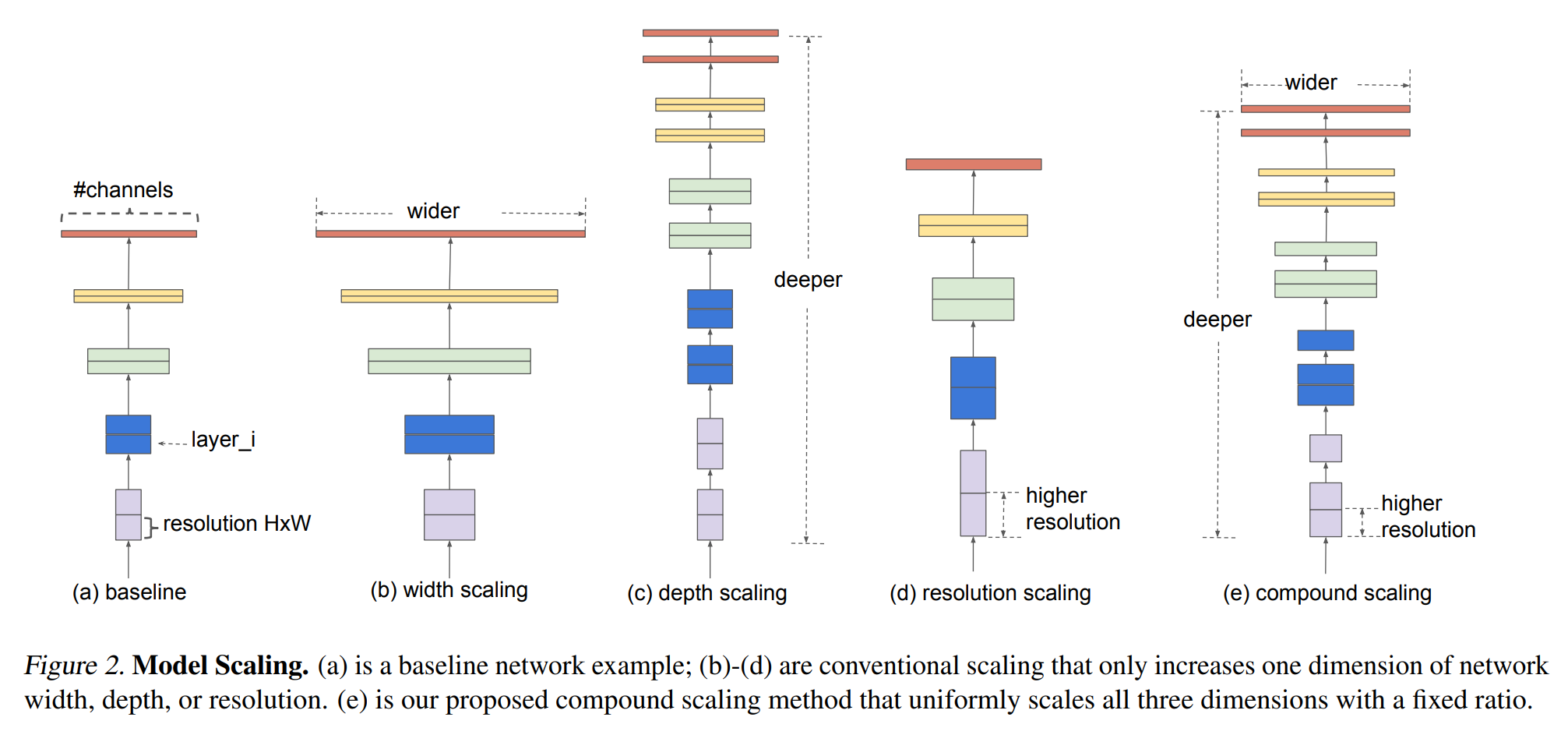
我们在尝试提升CNN的性能时总希望通过scaling来实现(b, c, d),作者发现仅对其中一个方面scaling性能很快会达到瓶颈。
compound scaling会起到更好的效果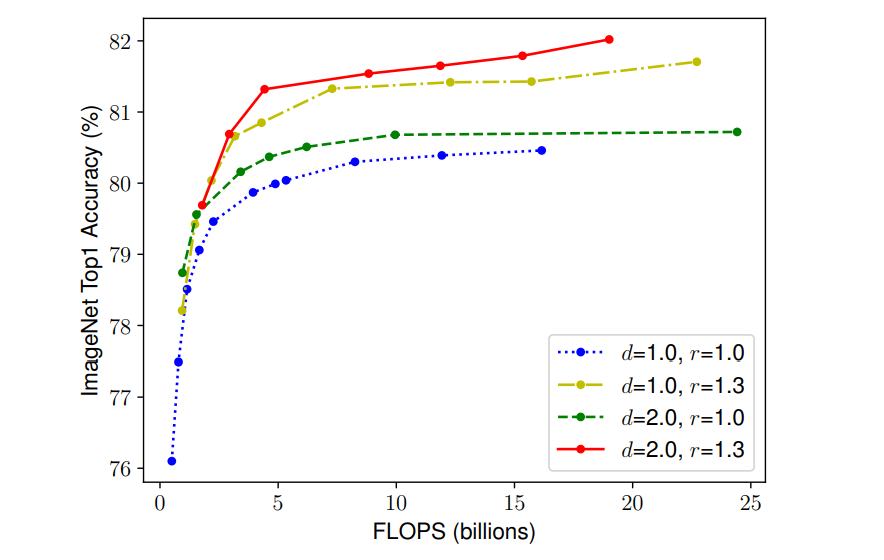
因此,作者提出了一种compound scaling策略,通过调整\phi来均衡地缩放d, w, r,通过多目标(Acc,target FLOPS=400M)的NAS来得到baseline:EfficientNet-b0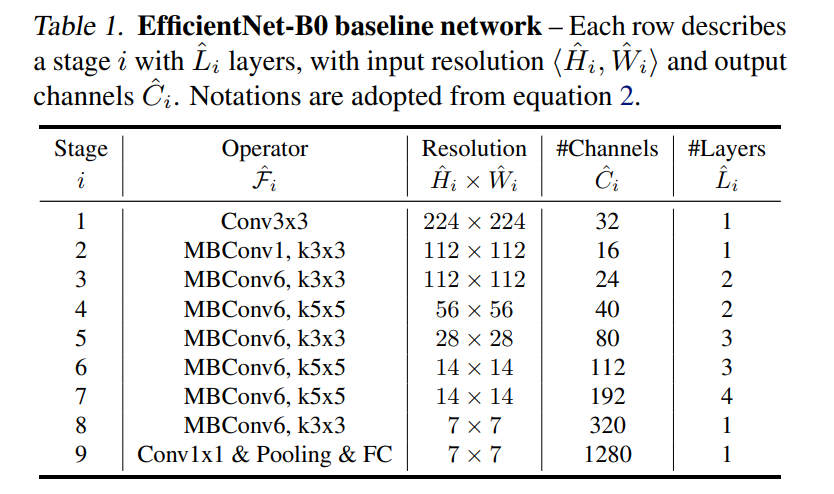
接下来调整\phi就能对模型进行compound scaling,得到EfficientNet-b1~b7,在小得多的params和flops基础上得到了相似或更好的top1/top5-acc
NAS with RL (ICLR, 2016)
作者认为神经网络的结构和连接可以用一个长度可变的字符串表示,从而可以用RNN作为agent生成这样的字符串,从而确定一个child network,在这个child network上validate的acc作为reward,计算策略梯度,更新RNN。
NAS based on Evolution (ICML, 2017)
作者进化出一个NA种群,模型个体在val上的acc作为适应度,每个进化步取出两个个体,杀死适应度较低的个体,适应度高的作为亲本进行下一步繁殖,变异,放回种群;
问题:搜索空间过大;作者提出了一个large-scale并行的方法,存在很多worker,它们共享种群这个文件系统,worker先到先得地取个体完成进化步;
MnasNet (Google, 2018)
Google使用基于RL的NAS,使用模型精度、参数量、训练时间三者的加权作为reward训练模型