3D Vision III & Sequential Data I - PointNet, 3D Conv, RNN
PointNet++
Quiz: PointNet 和 Conv 谁的 capacity 更强?
PointNet 把 ball 里面每一个点等而视之,丢失了relative coord的信息;Conv就没有,相当于在视野里 PointNet 对每个像素做了相同的 MLP,Conv 做了不同的 MLP;PointNet 是各向同性的,Conv 是各向异性的。
为什么很难把PointNet做成各向异性的?这么做相当于我们需要一个 MLP Field \displaystyle f(X_{r}) 关于相对坐标,人们做了一些改进。
改进:
- HyperNet:用别的网络预测MLP Field的参数
- KPConv:把16个kernel分布在ball里面(形成MLP Field),如果点不恰好在kernel的位置就用相近的kernel线性插值
3D Conv
我们还是想用Voxel+Conv解决问题:天然的各向异性更加简洁优雅;既有的问题是3D Conv太expensive,低分辨率下把一般的物体转换为voxel会有很强的information loss。有没有办法既占了各向异性,又让占用比较低?
Sparse Convolution
我们想只取出物体表面的Voxel,删掉其他的信息,全都当0处理。

什么都很好,高效,支持index,和Conv2d相近的开销和一致的translation equivariance;唯一的缺点是离散化 Discretization Error(实践里不太重要)。Implementation比较tricky,工程很复杂;目前SparseConv是工业界最常用的方法。小尺度(具身Grasp)可以先用PointNet探个路,大尺度(自动驾驶)喜欢用Sparse Conv。
有趣的其他任务但今年不讲:Mesh 生成,需要对 Mesh 求梯度;Implicit Function; NeRF, 3DGS
RNN
- Sequential Data: 语言是序列数据,处理序列数据的神经网络有 one to many 的 (img -> description),many to one 的 (action prediction),many to many 的 (video caption, video action classification on frame)
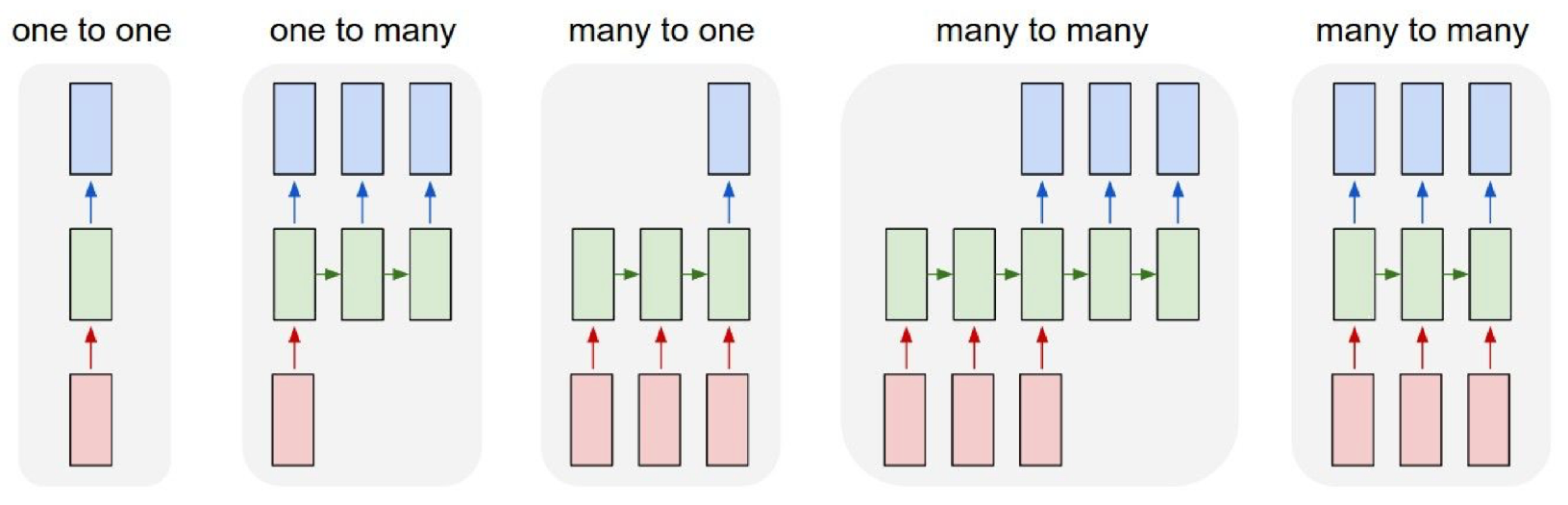
- 对于 Sequential Data,最基本的处理方法是 Rucurrent Neural Data,循环神经网络,RNN;它的关键思路是internal state:作为上一部分的内在输出,传送给下一部分作为输入,提供序列信息。换言之,存在一个recurrence formula: \displaystyle h_{t}=f_{W}(h_{t-1},x_{t}), 加工后得到输出 \displaystyle y_{t}=f_{W_{hy}}(h_{t})。你可以选择这样子
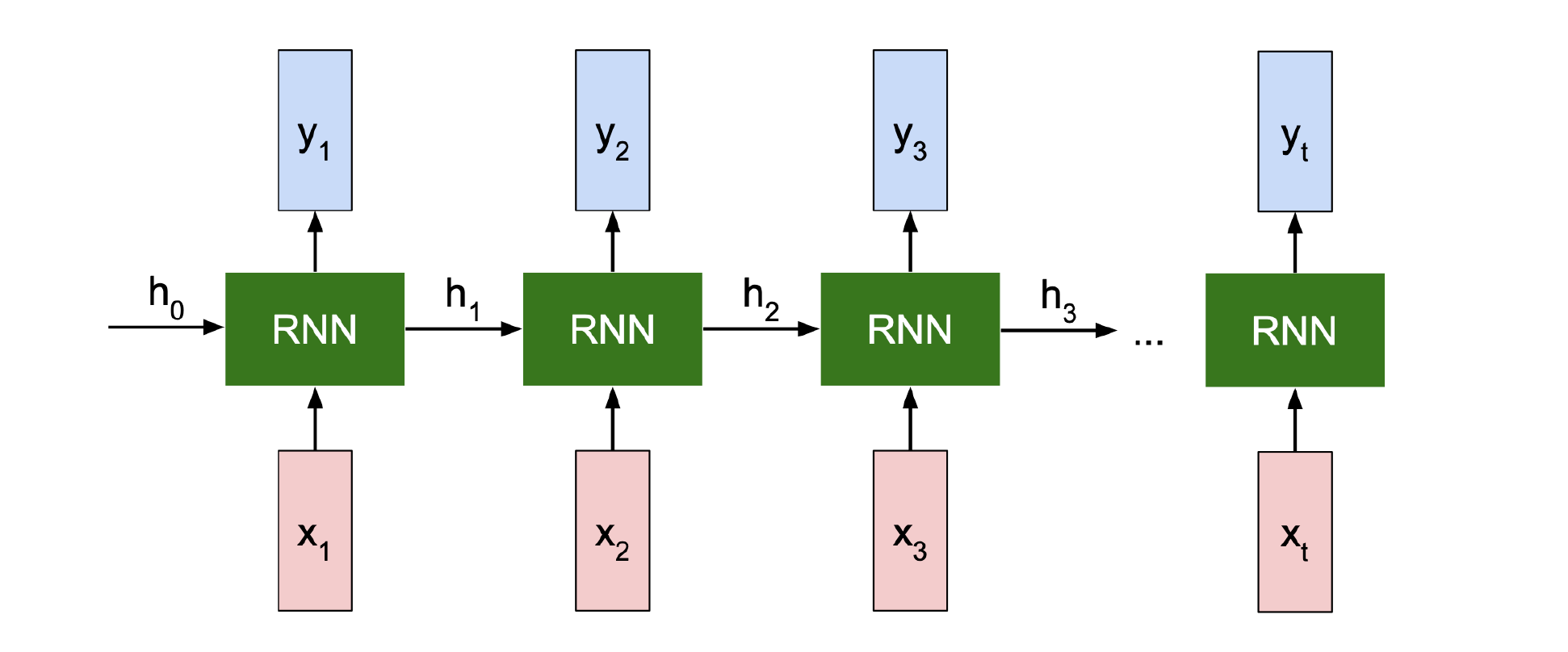 就是many to many,也可以选择只把最后一个 \displaystyle y_{t} 作为输出,就是many to one。请注意这里的每个 RNN 都是相同的,正所谓循环。
就是many to many,也可以选择只把最后一个 \displaystyle y_{t} 作为输出,就是many to one。请注意这里的每个 RNN 都是相同的,正所谓循环。 - Vanilla RNN: 学三个权重 \displaystyle W_{hh}, W_{xh}, W_{hy},用 \displaystyle \tanh 做激活函数。这样就有状态转移方程 \displaystyle h_{t}=\tanh(W_{hh}h_{t-1}+W_{xh}x_{t}),输出方程 \displaystyle y_{t}=W_{hy}h_{t}
- 例子:Character-Level Language Model;
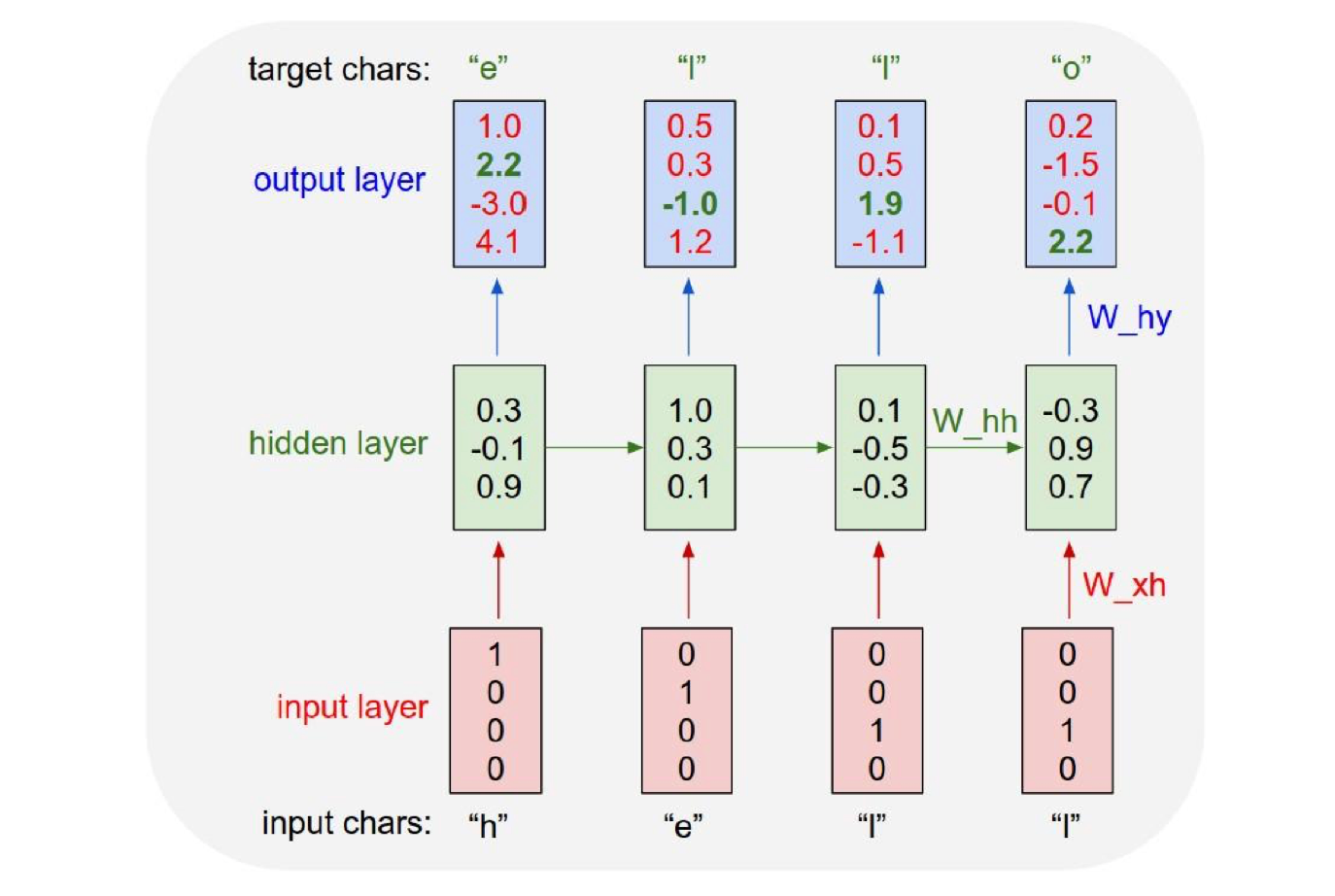
(1) 定义词汇表 (2) 词嵌入 (3) 训练:这里如何反向传播?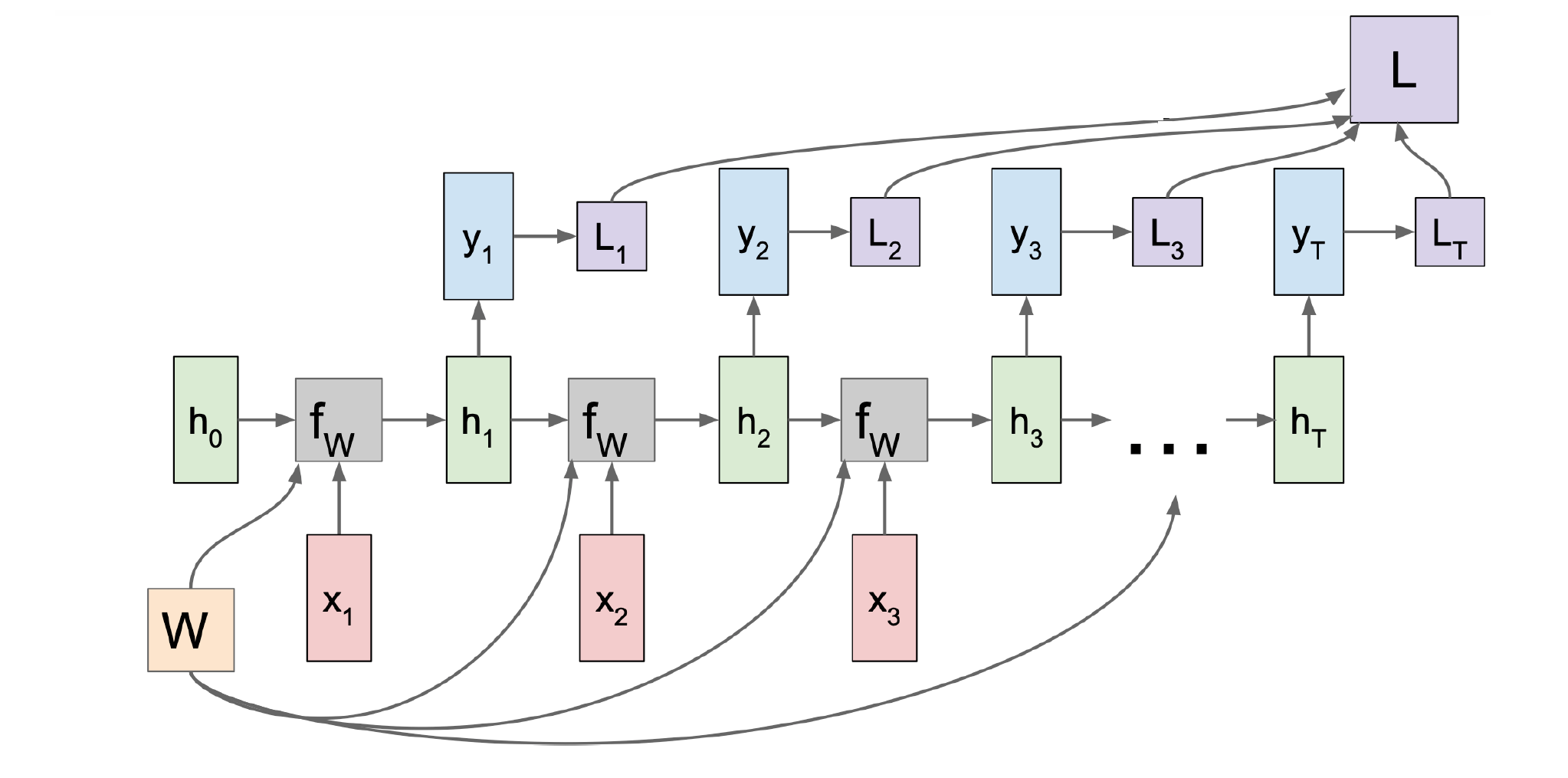
最后一个loss会一直回流到开头,\displaystyle L_t 要穿过 Recurrence \displaystyle t 次,依赖关系很长,计算复杂度很巨大;如何改进?且听下回分解
3D Vision III & Sequential Data I - PointNet, 3D Conv, RNN
http://localhost:8090/archives/cRZnhP4u