HPCGame@2026 Writeup
这是我参加 PKU HPCGame@2026 的题解。
A. 签到
见到代码的形式猜测程序输出自己,于是 copy 了代码提交 :D
B. 小北问答-超速版
Q1
Amdahl's Law 指出固定负载下加速比为 \displaystyle \frac {W_{s}+W_{p}}{W_{s}+{\frac {W_{p}}{p}}},其中 \displaystyle W_{s},W_{p} 分别表示问题规模的串行分量和并行分量,从而最大加速比极限是 \displaystyle \frac{W_{s}+W_{p}}{W_{s}}=10;Gustafson's Law 指出固定处理器数量下加速比为 \displaystyle W_{s}+W_{p}N,从而该系统加速比为 9.1
Q2
在 OpenMP 中,除非显式指定,否则在并行区域外声明的变量默认为 shared,每个线程访问的是同一个 sum 变量;OpenMP 不会自动为 sum 添加原子操作,存在数据竞争,结果不确定。
Q3
BF16 使用 1 位 sign,8 位 exponent,7 位 mantissa;NVFP4 使用 E2M1
Q4
在 https://xflops.sjtu.edu.cn/hpc-start-guide/parallel-computing/mpi/ 学习了 MPI 的常见 api:
- All-gather 操作将每个进程的消息拼接后放到到每个处理器上,它的对偶操作是 Reduce-scatter
MPI_Allgather(&local_val, 1, MPI_INT, recv_buf, 1, MPI_INT, MPI_COMM_WORLD); - 笛卡尔拓扑将进程排列为规则的网格
MPI_Cart_create(MPI_COMM_WORLD, 2, dims, periods, 1, &comm_cart);
Q5
查看 https://github.com/NVIDIA/nccl (version 2.28.9) 的 nccl/src/graph/tuning.cc, L149 检查到 NVLink, Tree, LL 下 hwLatencies 取值为 0.6 µs
- NCCL 2.12 引入的新功能称为 PXN,PCI×NVLink,因为它使 GPU 能够通过 NVLink 再通过 PCI 与节点上的网卡通信。
- In the topology in Figure 1, NIC-0 from each DGX system is connected to the same leaf switch (L0), NIC-1s are connected to the same leaf switch (L1), and so on. Such a design is often called rail-optimized. Rail-optimized network topology helps maximize all-reduce performance while minimizing network interference between flows. It can also reduce the cost of the network by having lighter connections between rails.
https://arxiv.org/abs/2307.12169 提到
- 在 HB 域内,互连需要支持大量的 any-to-any 通信,以训练不同的 LLMs
- 跨 HB 域通信仅发生在具有相同 rank 的 GPU 之间(即同一 rail 上的 GPU)
Q7
- cp.async 的数据本身也不经过寄存器;
- 通常只需要一个线程发起 TMA 操作,不需要所有参与的线程都执行相同的指令;
Q8
考虑 non-embedding 部分,单层参数量
FP16 下,梯度大小 M_{grad}=P\times 2\text{byte}= 32\times 12h^{2}\times 2 \text{ byte}
- Data parallel 下 ring all-reduce 时每张卡的发送量为 \displaystyle M_{grad}\times \frac{3}{4}\times 2 = 18 \text{ GB}
- Pipeline parallel 下每张卡的发送量为 \displaystyle 2\text{tensorSize}=2BSh \times 2\text{ byte}=1\text{ GB}
- Tensor parallel 下每张卡的发送量为 \displaystyle 32\text{ layers}\times 4\text{ ops/layer} \times BSh \times 2\text{ byte} = 96 \text{ GB}
Q9
Serving Large Language Models on Huawei CloudMatrix384 提到
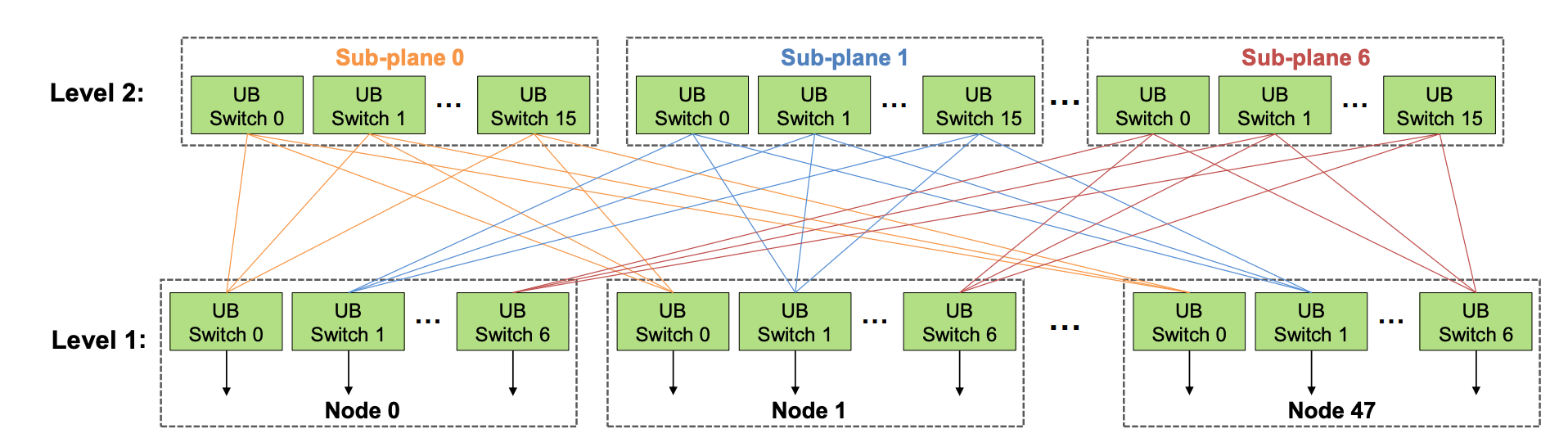

于是所求的系统级聚合带宽
Q10
- Loop 3 中,
k从 0 增加到 63 访问B[k][j],由于矩阵是行优先存储的,访问B[k][j]和B[k+1][j]的地址差值 = RowWidth × ElementSize = 512 Bytes - 这个 Stride >> Cache Line,所以完全没有空间局部性
- 地址映射到 Set 的跨度是 \displaystyle \frac{512}{64}=8,这样每次访问都跳过整个 Cache Line,从而 Cache Miss Rate = 100%
- 分成 8x8 之后正好每行 8 个 double 占一个 Cache Line,8 行数据索引分别是 \displaystyle S+8i, i=0,1,\dots,7,mod 64 互不相同,所以不会发生自我冲突
C. Ticker
修改一行 struct alignas(64) Candle { 即可。原先四个变量共计 32 Byte,鲲鹏 920 一个 L1 Cache 大小是 64 Byte,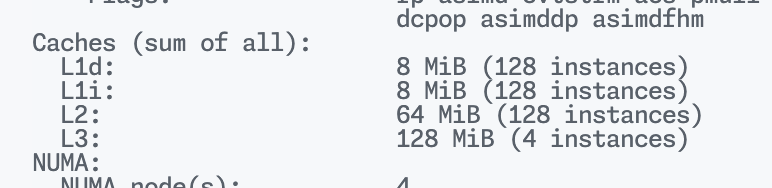 导致两个线程共用一个 Cache Line;线程 0 修改
导致两个线程共用一个 Cache Line;线程 0 修改 candles[0] 时,它需要独占该缓存行的所有权,导致线程 1 持有的同一个缓存行副本失效,线程 1 必须重新从内存或 L3 读取数据才能写入 candles[1]。
D. Hyperlane Hopper
本题要求一个并行单源最短路算法,我首先按照 Gemini 大人的指示实现了一个不含轻/重边的简化 \Delta-Stepping 算法,结果可以通过部分测试点的部分分。后来进行了一些无关痛痒的修改,包括使用 CSR 存图,连续内存提高缓存命中率,并行建图,循环复用桶之类的——这使得从部分测试点的部分分到拿到了部分测试点的全部分(过去了两个月已经不太记得了...)。继续实现一个标准的带轻边/重边 \Delta-Stepping,惊讶地发现它额外通过了一个 n>10^{6} 的测试点;无耻地特判合并这两种情况,就只剩下 n=10^{5},m=2\times 10^{5} 这种情形没有解决了。
分析指出对于 \displaystyle \frac{n}{m}=2 这样的稀疏图,\Delta-Stepping 会带来额外开销,于是对这个情况再特判了一个并行 SPFA 通过了这个测试点。
很不优雅的方案,很好奇官方解答。
E. 哪里爆了
到底哪里爆了!一路跟着 ssyrk_direct_alpha_beta_arm64_sme1.c 走到 ssyrk_direct_sme1_2VLx2VL(),ssyrk_direct_sme1_2VLx2VL,中间似乎有一个地方直接把 impl. 导向了其他地方而非 ssyrk 的真正实验。修复这一点后,
把这个 sstrk kernel 喂给 ChatGPT,它告诉我 ssyrk_direct_sme1_2VLx2VL 错误地只处理了「方阵且 stride 等于维度」的最简情况而没有处理 stride 逻辑。具体地,代码直接规定 const uint64_t ldc = n;,这导致不管实际上传入什么 stride,内部都直接用 n 作为行步长。修复方法是把 stride 真正传进去,调整 ssyrk_direct_sme1_2VLx2VL 实际采用的 kernel_2x2 把 stride 真的传进去,这样再相同地调整 ssyr2k 就解决了。
出题人似乎指出问题并不处在这里,而是一个更简单的地方...很好奇官方解答。
F. 小北买文具
本题要求使用 PLU 分解求解一个线性方程组 Ax=b,应该是比较经典的问题。题目介绍了分块 PLU 分解每次处理一个 BLOCK_SIZE 宽的面板,
- 把 [A_{11};A_{21}] 这一列面板复制到 buffer 里做局部分解得到 P_{1},L_{11},U_{11},再把行交换同步回整行
- 解 U_{12}=L_{11}^{-1}A_{12}
- 更新 \displaystyle A_{22}\longleftarrow A_{22}-L_{21}U_{12}
这样会更加 cache 友好。此外,对分块 PLU 做了如下 trick 优化
- 声明连续的内存做局部分解
getrf_panel_compact直接在panel_buffer上按紧凑行步长jb索引#pragma omp simdOpenMP 并行化外层行循环- U_{12} 的求解也一致地并行化列循环
- 三角求解时先按 ipiv 做在块内串行递推,再把已解出的块并行更新后续行
理清思路后把计划交给 Gemini 做实验,就完成了这题。
G. 显存不足
这题对我产生了一天一夜的折磨——本题希望我们在一张显存为 48GB 的 AMD W7800 GPU 运行 BF16 精度的 Qwen3-32B 模型的 prefill,禁止使用量化和剪枝,并有一定的性能要求。题意大概是希望我实现一个 Offload 技术。
Offload
以 BF16 加载 Qwen-32B,模型权重大小大约是 32B * sizeof(BF16) ~= 64GB;题目给出 100 条长度为 2048 tokens 的文本,KV Cache 是 2 x 64 layers x 8 heads x 128 dims x 2 bytes = 256 KB per token,这样 KV Cache 是 0.5GB;activation 大约也占据 0.5GB,这样整个显存占用就遗憾地来到 65GB。为了让 48GB 的 w7800 能跑起来,我们把 64GB 的模型权重拆成 N 部分卸载到内存上,只在推理到对应层时把对应的权重加载到显存里以降低显存需求。我们应用了 offload,在我的本地测试环境调整了大致的参数 N 使得显存占用尚可(一张 24GB 的 4090,使用 Qwen-8B 做实验),这导致性能不满足需求——
Sequence packing
出于无关紧要的(后来发现是致命的)失误,我没有注意到测试集所有的文本长度相同,因此我决定使用 sequence packing 合并 batch 来提高推理效率。传统情况下,当处理长短不一的文本时,为了保持一致的输入尺寸一致,要使用大量无意义的 padding token 把文本填充为统一长度,这样才能进行矩阵运算,这浪费了一部分算力。于是,sequence packing 决定将多个较短的序列拼接成一个较长的序列再输入模型,来避免了珍贵的算力被用来算 padding。这要求我们手动构建一个分块的 4-dims attention mask 并调用 flash_attn_varlen_func 来手动传入 causal mask。应用了如上两个策略后,我在本地实现了正确的 loss 计算结果并愉快地跑到了 ~16s,远低于 75s 性能要求,大胆提交!
错误的结果
Line 1: got=12.875000, expect=1.084397, rel_error=10.873 (>0.05)
神秘的是我的代码在评测机上会计算出错误的 loss。我花费一个晚上排除了 flash-attn 版本、torch 版本之类的毛病,并在当天夜间把目光投向了种种无关的事情之后终于盯上了 ROCm。线索:令 B=9 合并 batch,在评测机上的前 99 个测试点错误而最后 1 个测试点正确。调整涉及到合并 batch 的各种代码,直到我们要求 flash_attn_varlen_func 使用 ref 实现
os.environ["FLASH_ATTENTION_TRITON_AMD_REF"] = "1"
结果则回归正确。进一步检查 https://github.com/Dao-AILab/flash-attention ,很无语地发现 flash_attn_varlen_func 的 ROCm 实现存在一个传参错误。
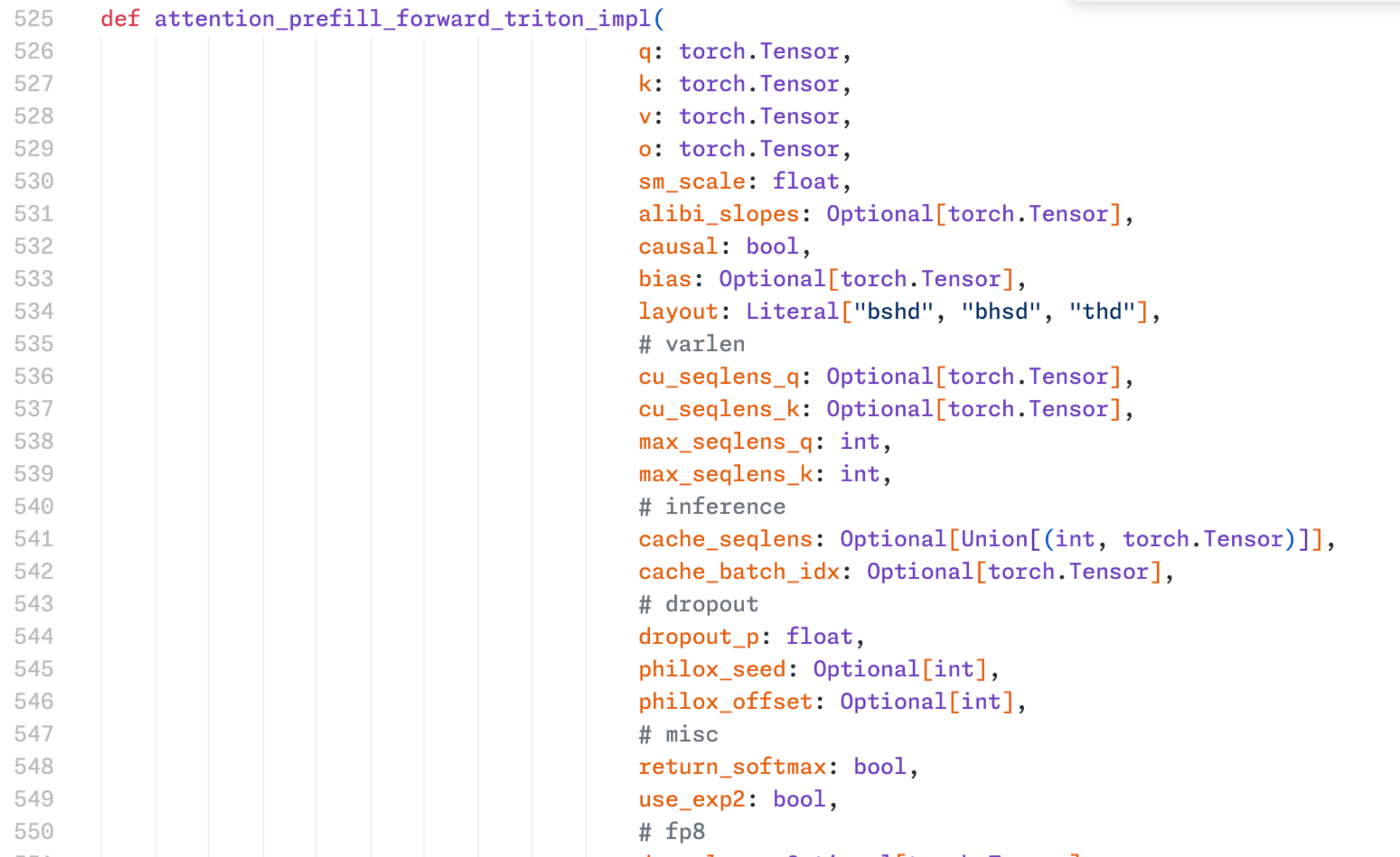
使用 thd layout 时,o_strides 是三维的
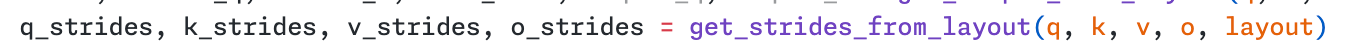
展开 o_strides 传参

但接收参数时只处理了 o_strides 为四维的情况,这导致在 AMD 显卡上使用 flash attention 计算 thd 布局的序列计算错误。

看来当初使用 bshd layout 就不会受此一难。提交强制使用 ref 实现的 flash_attn_varlen_func 获得 99.81 分,就没有再管这题。
排不到的 w7800 (╥﹏╥)
H. 流水排排乐
本题因为极其完善的 infrastructure 所以直接被 Gemini 秒了...给出的做法如下:
题目给出了一个 KDT-TPU 体系结构。对于任务 1:
- 设置 a0, b0, c0, a1, b1, c1 双缓冲
- 每段 50 cycles 中两个区域内必有一者在 load,一者在 add
- 设置 BLOCK_SIZE = 5376,虽然 VXM 浪费了 8 个 cycles 但是条件比较宽松从而通过
对于任务 2:
- SPM 分 6 个区域的话一个区域能放下 128\times 128=16,384 个元素
- 双缓冲 a0/a1、b0/b1,c 单块常驻在 SPM 上
- 流水是每轮 prefetch 下一块 A/B 的同时做当前块的 matmul
- job 粒度按 (M/BM)×(N/BN) 切分,每个 job 负责一个 128×128 的输出子块,这样就能通过测试
对于任务 3:
- 在任务 2 的基础上引入量化缩放,每块 A/B 额外带一个 scale 张量
- 三缓冲 ab0/ab1/ab2、bb0/bb1/bb2 及对应 as/bs
- 流水是当前块 matmul -> 加载 k+2 块数据 -> 对 k+1 块做 broadcast scale 然后 matmul,这样就能通过测试
对于任务 4:
- 按照 Flash Attention 的做法按 Q 的行方向切 job,每个 job 处理 128 行
- 在线 softmax 维护行最大值 m_{i} 和归一化分母 l_{i},每个 KV 更新一次
- 循环按步长 2 展开:同时 load k0/v0 和 k1/v1,连续做两次 QK^T + softmax + 加权累加,减少 load 等待
- 奇数块剩余用 fallback 单步处理
- 最后 o_tile / l_{i} 完成归一化后写回,这样就能通过测试
辛苦的出题人 (╥﹏╥)
I. Python 笑传之吃吃饼
本题要求我们搓一个 torch.compile 出来(x) 题目要求尽可能优化 cal 函数的时间而可以无视 gc 函数的执行时间,Gemini 指出可以通过在 gc 编译阶段,通过符号计算和自动微分,将 cal 函数所需的全部数学工作提前完成,生成针对性的 C 代码来最大限度优化 cal;这相当于自行完成 autograd 的工作并且提前固化计算图、自动微分。AI 很快地完成了相关工作也就没有再操心细节 :(
J. 古法 Agent
本题要求我们完成一个字符串匹配问题。计算若干模式串 P_{1},P_{2},\dots,P_{k} 在文本串 T 中的匹配次数之和,其中P 和 S 匹配当且仅当 P 和 S 完全相同或只有 1 个字符不同,其余位置完全相同。特别地,附加条件是在评测机环境 Intel Xeon 8358 32 Cores, -O3 -fopenmp -march=native 上平衡其他部分的工作负载,动态控制总功率 <= 600W。
Bitap
选手群透露题目给定的 3s 时间非常宽松,特殊构造了数据以使得卡掉复杂度依赖数据的某些特殊性质的做法,以及「如果你找到了正确做法会发现解法非常简单优雅」,Bitap 方法似乎很符合这个描述。
给定模式串 P\in V^{m},文本串 T,我们首先从 P 计算 v 个字符掩码表 mask,维护一个长度位 m 的位数组 D,初始值 all 1;每读一个字符t,更新D = (D << 1) | mask[t],最终 D 的最高位为 0 代表匹配成功。简单扩展可以使得 Bitap 容许恰好一个位置字符不同,只需要维护两个位数组:D0 = (D0 << 1) | mask[t]、D1 = ((D1 << 1) | mask[t]) | (D0 << 1)。算法的时间复杂度是 O(m+|V|+|T|),显得非常没有冗余的算力浪费,让我很信服这个做法就是所需的。
毕竟是 HPCGame,首先对 Bitap 做并行化。注意到模式串长度给定为 64-bit,这样一条指令就可以搞定一次运算;进一步使用 AVX-512 指令集,一条指令就可以处理 512 位,8 个模式串的状态更新。对题中所需的功耗控制策略,加入了当接口返回的系统功耗接近阈值时 std::this_thread::sleep_for 掉一部分进程的策略。
结果并没有展现令人愉快的性能 (╥﹏╥). 对阈值做了调参之后,不含其他部分的工作负载的测试点可以做到 ~3.04s>3s,含有其他部分工作负载的测试点可以做到 ~8.5s>6s,profiling 也没有发现某个环节花费显著多的时间。
Hash
难道所需的「简单优雅的算法」不是这个?和 GPT & Gemini 辩论几轮后,决定试着用一下 Rolling hash,方法是对文本每 32 字节窗口计算滚动哈希,利用一个简单的静态哈希表(65536 个桶)查找模式串的左右半部分,这也可以用 AVX-512 一次性比较 32 个模式串的 hash;这带来了更差的性能,好吧这可能就是依赖数据的解法(?
最终提交了 Bitap 的版本,拿到了 91.39% 的分数,事后想可能是实现存在一些问题。
L. 稀疏注意力
写到这里已经是最后一天,时间所限只好开启代理人战争(x),重金购入 Claude Code 使用 Opus 4.6 的力量!karpathy/autoresearch 和近来许多观点都认为 Agent 主要是一个强大的做题家,构建一个闭环的 eval 环境并令 Agent 在环境内迭代升级能够最大激发出 Agent 的性能。本题恰好已经提供了 benchmark,可以直接让 Opus 自行迭代打怪。
题目
题目要求使用 Triton 或 TileLang 实现一个分块 Top-K 稀疏注意力算子:给定输入 Q, K, V, 稀疏索引 indices,要求计算输出张量 O;要求在 H20、A100、Ascend 910B 上实现正确计算,在 H20 上优化性能打榜。
实现
Opus 使用了这些 trick 提升性能
- 在线 softmax:无需把所有 attention score 存入 HBM 再做 softmax,而是维护三个运行变量增量更新
- GQA:依照题目要求实现了一次 kernel 实例同时处理
G个 query - 编译期常量:使用
tl.constexpr标注让编译器做循环展开、寄存器分配和向量化,消除运行时分支开销 - 按 D 分档内核:分 D\leq 64 和 D>64 分开处理,两个档位分别调优 warp 数和 pipeline state 数
- Causal mask 融合:掩码直接在 SRAM 内与 score 计算融合,无需额外的 mask tensor 读写
在本题上,结果的性能是第一名的 68.09%.
M. 真忙的管理员-MapReduce SpGEMM
题目要求实现一个大规模稀疏矩阵乘法,计算 C=A\times B 每行的 Top-K 结果。我以同上的方式驱使 Opus 完成这题。
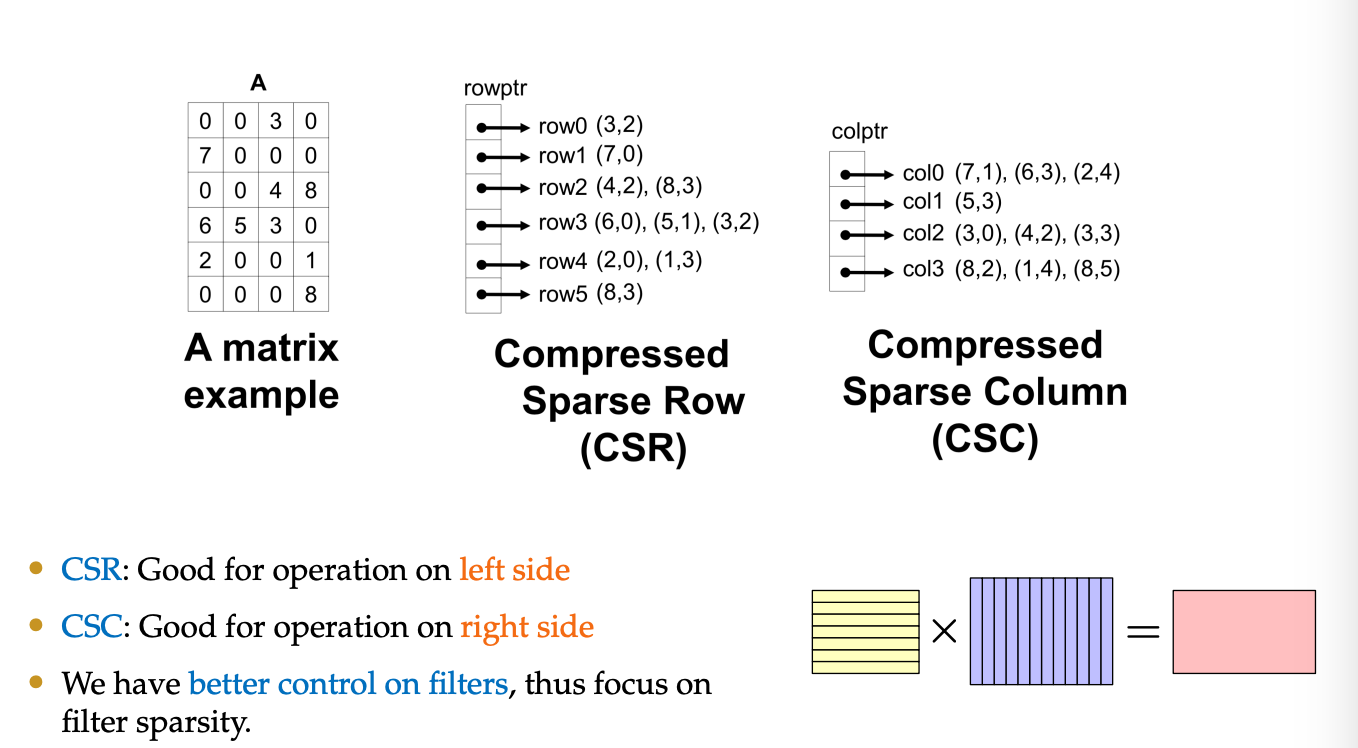
稀疏矩阵乘的做法很清楚,大致是
for k in shared_dim:
for (i, a_val) in A[:,k]: # A 第 k 列的所有非零元
for (j, b_val) in B[k,:]: # B 第 k 行的所有非零元
C[i][j] += a_val * b_val
它的时间复杂度是 \displaystyle \mathcal{O}\left( \frac{\text{nnz}_{A}\cdot\text{nnz}_{B}}{K} \right),主要的瓶颈是 i/o 都没有什么空间局部性,通常是 memory-bound 的;要实现并行化,还面临各 rank 负载不均衡、MPI 通信开销大的问题。本题 Opus 的实现结果
- 每个 rank 负责
i % size == rank的所有 A 行 - B Allgather 广播给所有 rank,将 B 的 COO 三元组按行聚合成
k -> [(j, val)]的 hash table 以做到后续 \mathcal{O}(1) 的查询 - C 矩阵每次只维护一行防止爆内存
- 优化 Top-K 排序
基本实现了稀疏矩阵乘,但没有做什么优化。肉眼可见它
- 没有解决 memory-bound
- 没有解决负载不均衡
- 题目允许我们牺牲计算精度来进一步加强速度,我们也没有这么做
此时我也无力再做优化,提交了这个版本,获得 78.29% 的分数。
后记
进入 2026 年 agent 前所未有的强大地消解了人类在这类竞赛中的价值,构建越完善的评测系统、越高的题目质量越迅速地被 ai 打爆 (leavelet, 选手群)(x)。对我来说在八天里开始几天 ai 还是 copilot,过了半程我就成为 copilot 了,主要承担理解 ai 的思路、搬进自己脑子里、review 并丢给 ai 实现的功能。如果本身对题目涉及的相关知识有比较充分的了解,那么这个过程是很愉快的——把人从机械性工作里解放出来;如果没有什么了解仍然硬上就相当痛苦——把人丢进 copy-paste 抽卡循环里,没法把控 agent 的工作方向。如果没有主动从做题过程里吸收知识的意识,我从这场比赛里获得的知识比起没有 agent 时应该显著减少——新手恐怕有可能永远是新手,我这样的初级 coder 应该如何面对这样的情况尚是个问题。
今年第一次参加 HPCGame,最终得分是 1696.93 分,校内排名 9,还是比较快乐的。尽管评测机还是出了不少锅,作息跟着集群负荷波谷走()但同样肉眼可见维护集群同学的辛苦;高的题目质量也贡献了愉快的参赛体验!个人而言主要在这次 HPCGame 里接触了未曾了解过的 MPI 相关优化,学习了一些 infra 的基本内容;了解一个算法 - 分析它的理论性能上界 - 用各种不知道会不会起效的 trick 尝试接近这个上界是一个挺有意思的 pipeline,「评测」带来正反馈的速度也远快于 research 时尝试和修复各种问题,为做题过程带来了相当的乐趣。
祝越办越好!