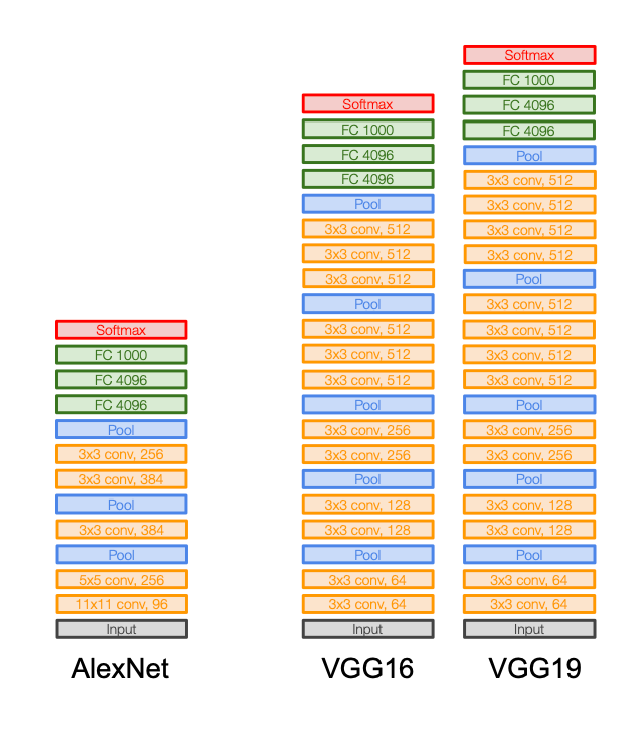
VGGNet
相比 AlexNet 有很好的涨点,特征是:
- Small filters (3x3 Conv kernel)
- Deeper networks (16-19 layers)
为什么小的 filter 能够带来更好的效果?
Receptive Field 感受野
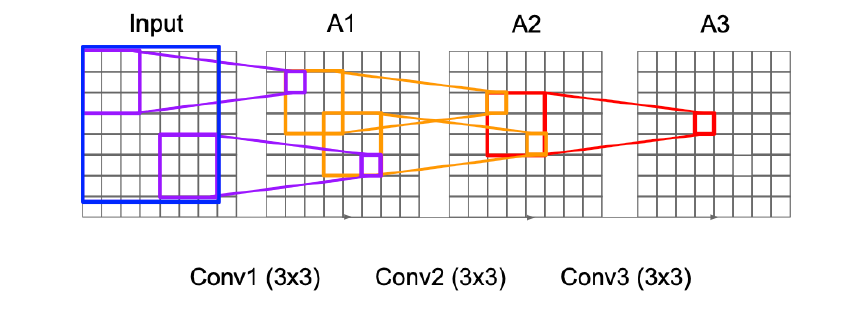
像这样3次 3x3 Conv 的感受野大小是等于1次 7x7 Conv 的,理论上我们能够学出同一个函数,区别是什么?
- capacity:3次 Conv 有 3次 ReLU,更多的非线性层带来了更加磅礴的capacity
- 更少的参数:3次3x3 Conv的 parameters:\displaystyle 3\times 3^{2}C^{2},1次7x7 Conv的 parameters:\displaystyle 7^{2}C^{2}(之前没搞懂这里,特别留意:1) 事实上是 \displaystyle C_{\text{in}}\times C_{\text{out}};2) 一个输出通道上的一个元素是所有通道的卷积结果之和;换言之,filter 是一个 Cin x 3 x 3 的张量)
为什么我们要涨感受野?考虑多分类问题
- 需要看整个物体而不是局部(一只脚或者手)才能明白这是个什么,所以最后的感受野一定要是全图(不过走到最后一步 FC Layer 进行了 flatten,所有 pixel 感受野的并集也确是全图)
- 但是为什么要 deeper?为什么不直接上一个 h x w 的 filter?我们是进行一个从图像空间变换到最后的线性的语义空间的过程,中间信息一定是慢慢提取需要特别足够的capacity的,或许可以想象一个 Conv Layer 提取了一个局部的信息,那么我们最后要组合这些局部才能判定这到底是个什么玩意;所以AlexNet应该属于underfitting
灵魂画手👇
题外话:1x1 Conv 是干什么的?信息并没有和周围任何pixel互动,只是conv一下自己,一般只在segmentation的最后一层用一下
结论:自 VGG 以来,3x3 Conv 成为了最流行的 Conv
ResNet
上次我们已经接触过ResNet的思想:梯度消失 => SkipLink => 更好的bwd;ResNet的一个block是两个 3x3 conv+skip link;depths很著名的有50,更深的101,152;太深的params太多,但今天也不太在乎了;倒是端侧大模型很在乎
对于 ResNet-50+,有一种 bottleneck 替代: 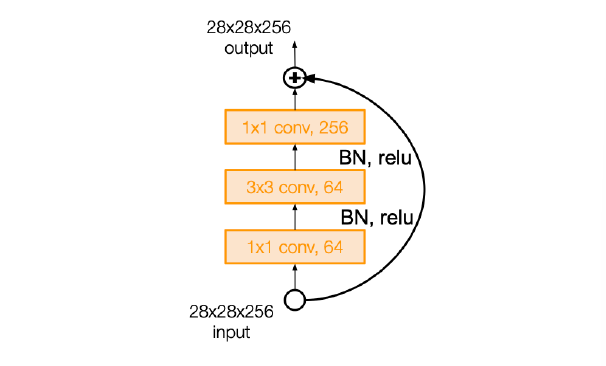
- 减小 params 和 memory:params 原来是\displaystyle C\times C\times 2\times 3\times 3=18C^{2},现在是\displaystyle C\times \frac{C}{4}\times 1\times 1+3\times 3\times \frac{C}{4}\times \frac{C}{4}+ \frac{C^{2}}{4} = \frac{17}{16}C^{2},大概是 1/18
- 增加了非线性度
- 以更小的感受野为代价:从 9x9 到 3x3(不过都50层+了,感受野大小确实不太在乎)
关于设计layer的思想: 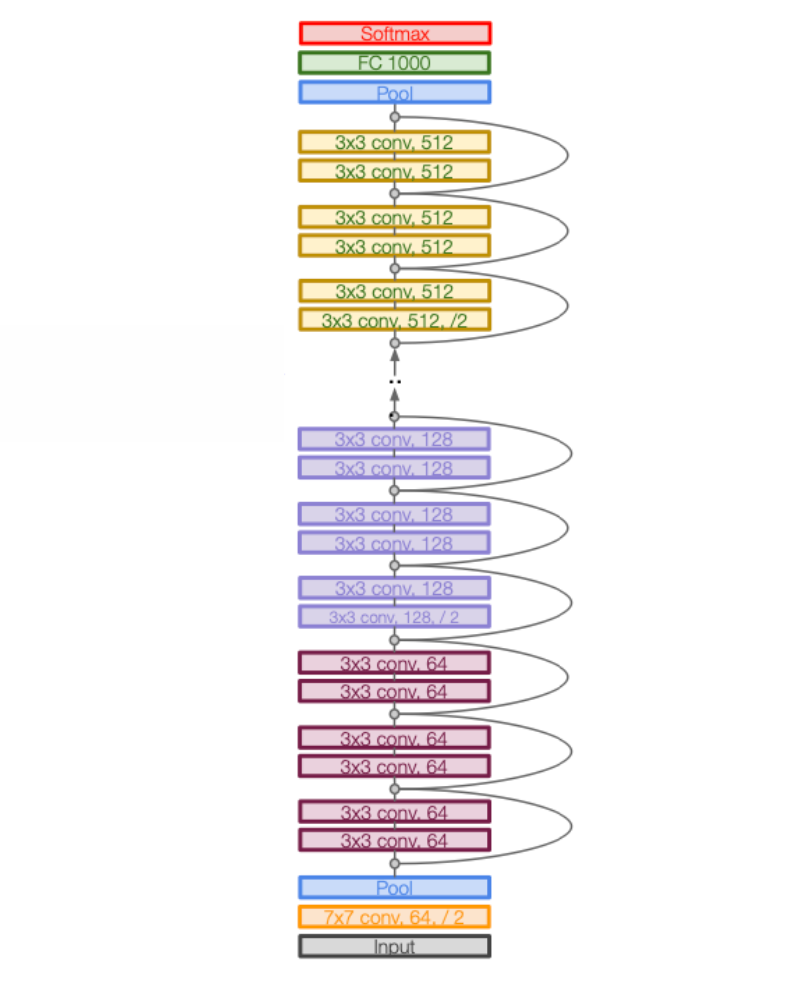
- 每次进行步长为 2 的 3x3 conv,channels 相应地加倍:我们不希望一次操作损失太多的信息,慢慢地把信息从分散的集中到 channels 维度上
- 观察一下:224x224x3 -> 112x112x64 -> ... -> 56x56x128 -> ... -> 7x7x2048(32次) -Global Avg Pooling-> 1x1x2048,ResNet的depth就由每一坨用多少个residual block决定(50/100/150)
- 分析 bottleneck module:params 和 memory 都得到了很好的优化;瓶颈机制也可以丢掉不重要的信息
- Training details:
- 每个 Conv 必加 BatchNorm
- Xavier
- SGD + Momentum
- lr=0.1
- batch size=256
- ...
ResNet 魔改...
- DenseNet (2017)
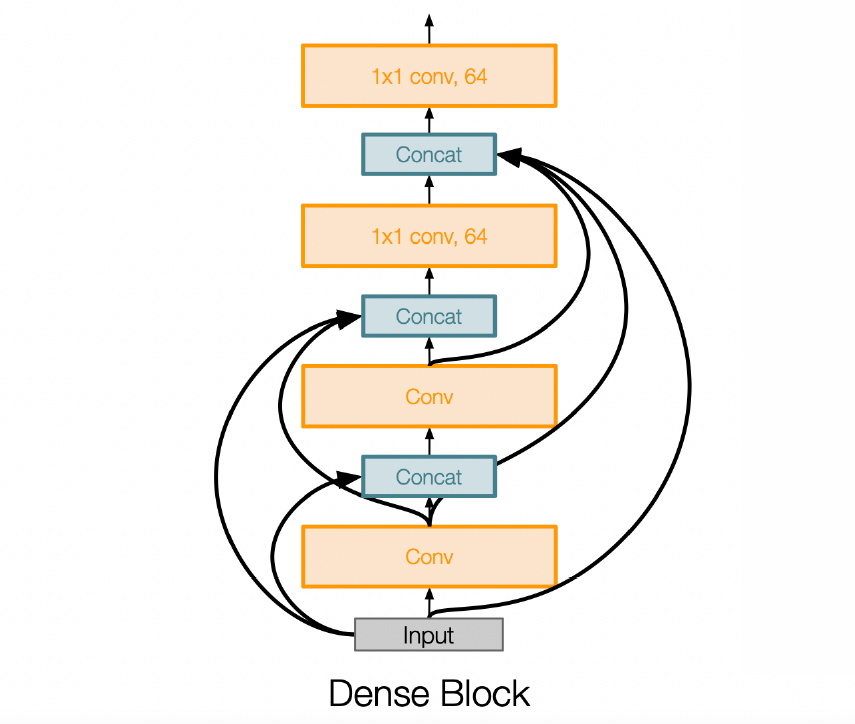
效果是 50-layer 的 DenseNet 比 ResNet-152 好 - MobileNet (2015)
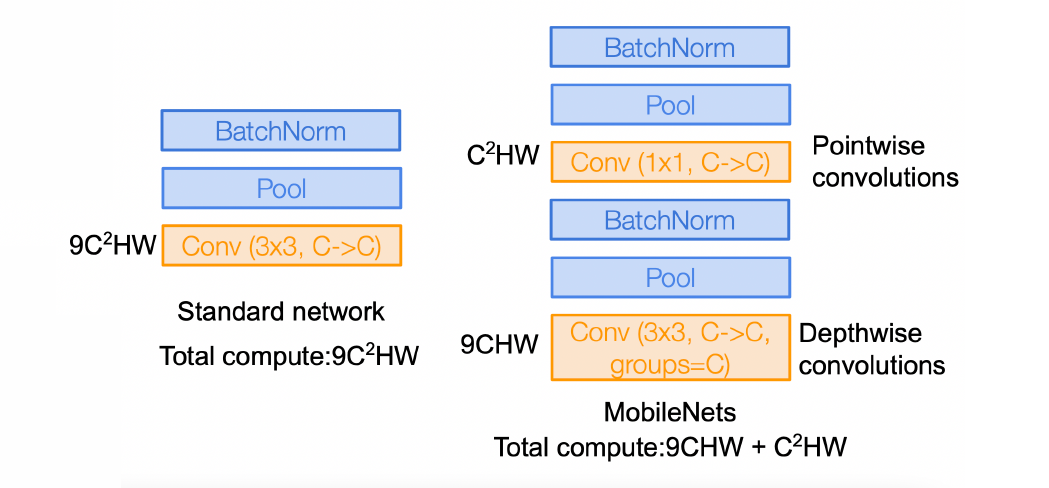
- 所以,架构是否也是可以learn可以train的?想法特别好,问题是搜索空间过于巨大;有一个 NAS Neural Architecture Search with RL (2016)
我没太明白这个方法的求导怎么进行
Segmentation
不同的任务颗粒度 granularity 是不同的。
到今天我们学习解决的问题也是递进的:binary classification -> multi classification -> image segmentation!
- 传统cv认为的segmentation只包括把图片里相同的物体group成一个mask
- 今天我们还能做semantic segmentation,还要给mask加上semantic flag;
- 再难一点,可以做instance semantic segmentation:把图片里不同的羊分开!
- segmentation的问题到今天甚至还有价值:多模态的大模型还没有统治这个方向,llm处理这个并不好
Anal.
- Semantic Segmentation 输出 dense 的结果:要得到一份掩码图像,我想这导致我们的设计思路和上面VGGNet/ResNet都是不同的
- 输出比输入信息一定少了:颜色只剩代表类别的块块了,并且我们也一定不能全部不pooling不stride地conv走到底,信息没有得到任何提炼;还是需要先降维后升维

我想想,输入是 3xHxW 的,输出 HxW,我的想法是浓缩到头然后把初始的 image skiplink 过去...
Auto-Encoder
很好理解 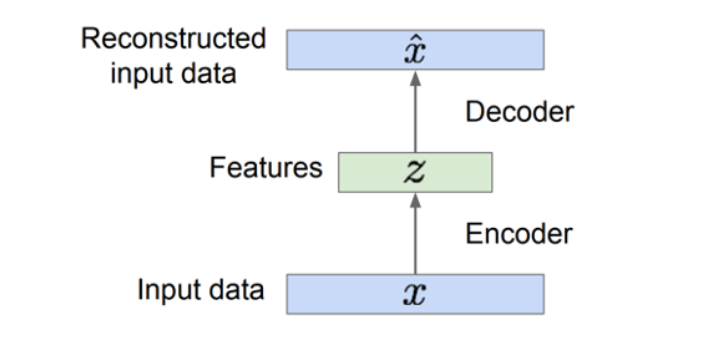
基于上面的想法,给出了这样的结构(Learning Deconv, ICCV 2015)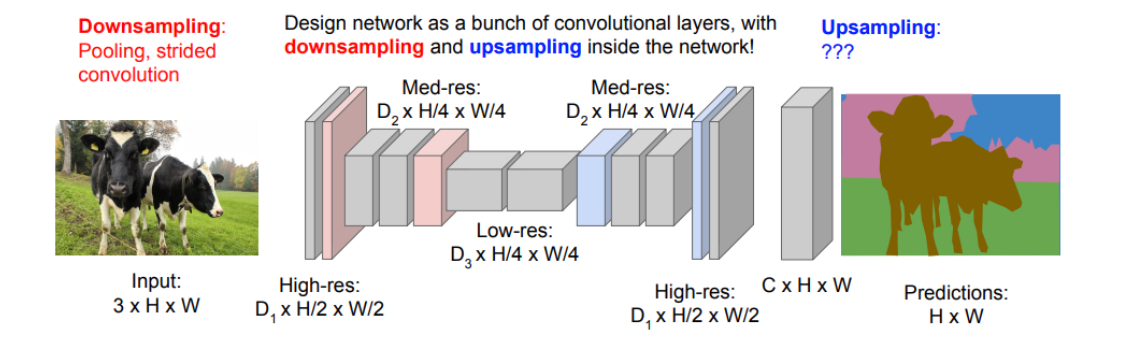
这里面引入的新操作是:如何进行 Upsample?
Learnable Upsampling: Transposed Conv
Downsampling 可以是rule-based的(max,avg)也可以是learnable的(stride=2 conv),Upsampling就很难rule-base了,我们想要一个learnable的
我觉得看1D-transpose的情况会特别好理解: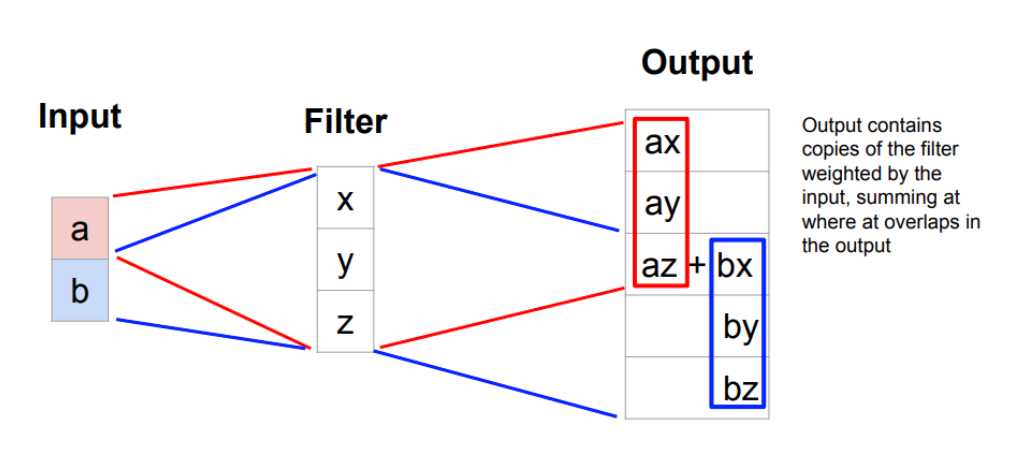
从矩阵角度也可以看出来为什么叫 "Transpose" 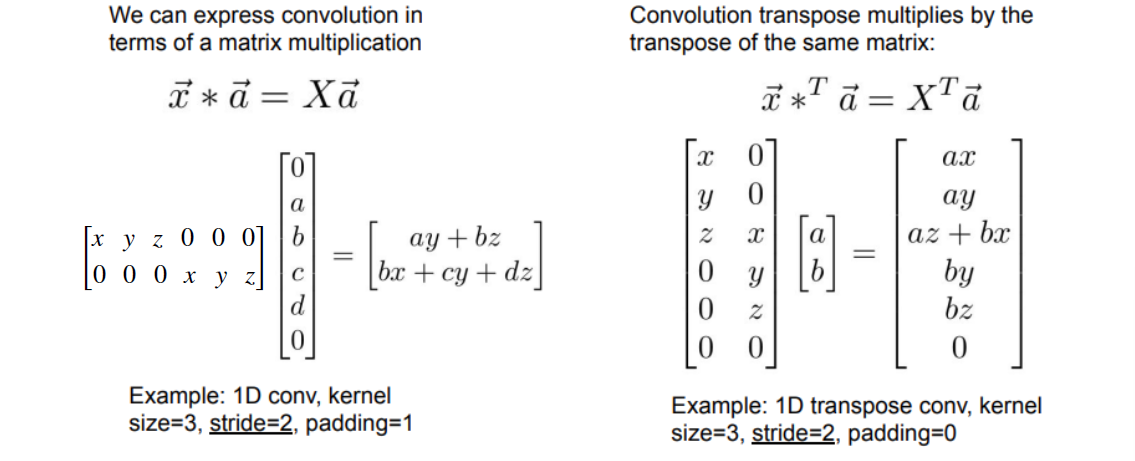
2D-Transpose 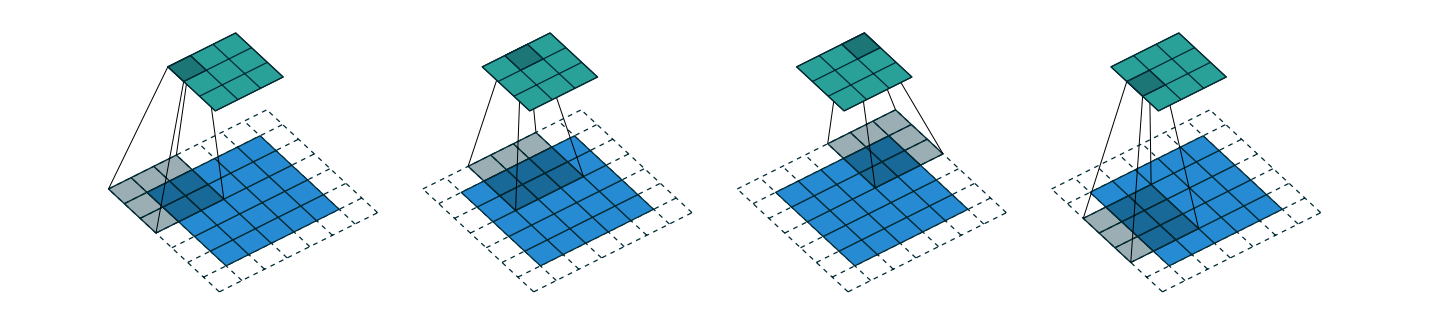
A guide to convolution arithmetic for deep learning
Anal. of Bottleneck
- downsampling的过程receptive field涨的很快,能够感知全局;更好的global context
- 当然降低了memory
- bottleneck结构的问题是可以想象难以还原全图:想象bottleneck降到了1x1xC,可能这样的空间能记住图片大概哪一块有什么类别,可是我们想要还原到pixel级别的边界清晰的类别就很难,信息绝对已经丢失了
我想想,我觉得 skiplink original 真的很好!
UNet
果然有人想到了这么做!
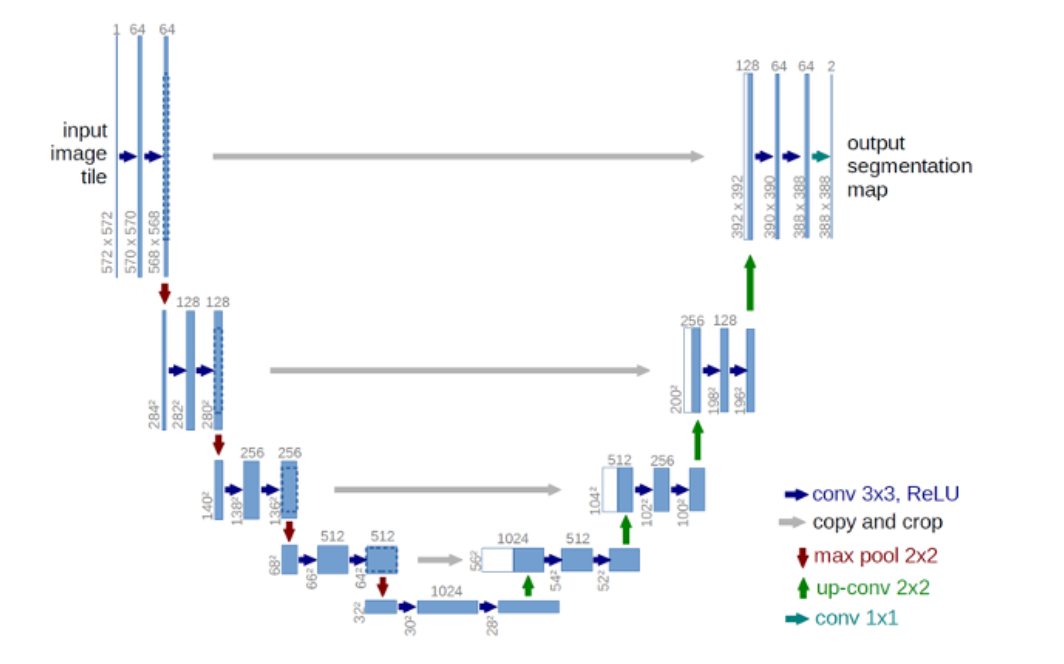
bottleneck现在只需要提供global context,在较小的计算负担下得到图片有哪些类别,具体边界如何由up-conv部分的结构决定
UNet 魔改...
- DeepLab
- UperNet
Metrics
Segmentation 问题的metrics要如何度量?
- pixel accuracy:把每个pixel当作一个分类问题,统计所有pixel的top1 acc或者top5 acc
问题:数据集的pixel分布很不均匀,自然能想到reward hacking方法是我们把整个图片都分类成天空!或许能够80% acc,但这完全不是我们想要的 - Intersection over Union
对每个 mask,我们定义 \displaystyle \text{IoU}=\frac{target\cap prediction}{target\cup prediction},取所有 mask 的 mean IoU
IoU 达到较高的值很难,50% 就很不错了